Auslese von CSV- und XML-Dateien in Databricks und das Zusammenspiel von SQL und Python
Mit Databricks begrüßen wir bei uns unseren neuesten Technologiepartner – und möchten diesen im Folgenden zunächst kurz vorstellen. Databricks ist eine cloudbasierte Plattform für die Verarbeitung und Analyse großer Datenmengen. Sie kombiniert die Leistungsfähigkeit von Apache Spark mit einer intuitiven Benutzeroberfläche und bietet umfassende Möglichkeiten zur Integration unterschiedlichster Datenquellen, zum Aufbau komplexer Datenpipelines und zur Anwendung von Machine Learning. Zusätzlich unterstützt die Plattform Delta Lake für eine zuverlässige und skalierbare Datenverarbeitung sowie MLflow zur Verwaltung von Machine-Learning-Projekten. Dank dieses breiten Funktionsspektrums ermöglicht Databricks eine effektive Umsetzung moderner Datenstrategien und liefert wertvolle Erkenntnisse für datengetriebene Entscheidungen.
Dieser Blogbeitrag richtet sich an alle, die neu in die Welt von Databricks einsteigen und erste praktische Erfahrungen mit der Plattform sammeln möchten. Er bietet einen verständlichen Einstieg, erklärt die grundlegenden Konzepte und Funktionen und zeigt anhand einfacher Beispiele, wie sich CSV- und XML-Dateien auslesen lassen. Außerdem erfahren Leserinnen und Leser, wie sich SQL und Python innerhalb von Databricks effektiv kombinieren lassen, um leistungsfähige Datenlösungen zu entwickeln.
Databricks-Notebooks
Databricks-Notebooks sind das wichtigste Mittel zur interaktiven Codeentwicklung und -ausführung. Das Ausführen von Code in einem Notebook erfordert Rechenressourcen, die von Clustern bereitgestellt werden. Ein Databricks-Cluster ist eine Gruppe von Rechenressourcen und Konfigurationen, auf denen Data-Engineering-, Data-Science- und Data-Analytics-Workloads ausgeführt werden können. Diese Workloads werden als eine Reihe von Befehlen in einem Notebook oder als automatisierter Job ausgeführt.
Databricks-Notebooks ermöglichen die zellenweise Ausführung von Code. Dabei können mehrere Sprachen in einem Notebook gleichzeitig verwendet werden. Databricks-Notebooks unterstützen Python, SQL, Scala und R. Eine Sprache kann bei der Erstellung eines Notebooks ausgewählt werden, was jedoch jederzeit geändert werden kann. Befehle zu Beginn einer Code-Zelle ermöglichen zudem die Ausführung von Code in anderen Sprachen als der Standardsprache des Notebooks. Dazu wird zu Beginn einer Code-Zelle beispielsweise %python für Python-Code oder %sql für eine SQL-Abfrage geschrieben.
Um in Databricks ein Notebook zu öffnen, wird auf den Reiter „Workspace“ navigiert, ein passendes Verzeichnis ausgewählt und auf „Create“ „Notebook“ geklickt.

Auslese von CSV- und XML-Dateien
Neben der Verbindung zu einer Datenbank, um Daten abzufragen, können in Databricks auch Daten aus z.B. CSV- und XML-Dateien verarbeitet werden.
1. CSV-Dateien
CSV-Dateien lassen sich innerhalb eines Notebooks auslesen und in Delta-Tabellen schreiben. Auf die Delta-Tabellen kann mit gängigen SQL-Abfragen zugegriffen werden. So können die Daten angezeigt, geupdatet, gelöscht, mit anderen Datensätzen gejoint werden und vieles mehr.
Als Beispiel werden folgende Daten im CSV-Format betrachtet:
Date,Product,Sales,Quantity
2024-01-01,Product A,100,2
2024-01-02,Product B,150,3
2024-01-03,Product A,200,4
2024-01-04,Product C,250,5
Zunächst wird der Inhalt der CSV-Datei in einem Dataframe gespeichert. Ein Dataframe ist eine in Python verwendete zweidimensionale, tabellenartige Datenstruktur. Mittels option() können mehrere Einstellungen vorgenommen werden. So wird z.B. festgelegt, dass die Datei einen Header enthält und ein Komma als Trennzeichen verwendet.

Das Dataframe lässt sich in einer Delta-Tabelle speichern. Mit format() wird festgelegt, dass es sich um eine Delta-Tabelle handelt. Durch mode(“overwrite“) wird die Tabelle überschrieben, wenn sie schon existiert. Der Name der Tabelle wird beim Speichern mit saveAsTable() festgelegt:
df.write.format(„delta“).mode(„overwrite“).saveAsTable(„default.csv_test“)
Anschließend kann die Tabelle mittels einer SQL-Abfrage ausgelesen werden. Mit %sql ist es möglich, SQL-Abfragen innerhalb eines Python-Notebooks auszuführen:

Das folgende Beispiel zeigt, wie mithilfe von read_files() die CSV-Datei auch direkt mit SQL ausgelesen werden kann:

2. XML-Dateien
XML-Dateien können ebenfalls innerhalb eines Notebooks ausgelesen und in Delta-Tabellen geschrieben werden. Hierbei lassen sich alle Knoten einer XML-Datei auslesen. Um einen Knoten auszulesen, muss der dazugehörige Knoten-Tag (der Wert zwischen „<“ und „>“) angegeben werden.
Bevor die Knoteninformationen samt Unterknoten in ein Dataframe geschrieben werden, wird zunächst die Logik des Auslesevorgangs mit folgender Beispiel-XML-Struktur betrachtet:
<knoten1> #Ebene 1
<knoten2> wert2 </knoten2> #Ebene 2
<knoten3> wert3 </knoten3>
<knoten4>
<knoten5> wert5 </knoten5> #Ebene 3
<knoten6> wert6 </knoten6>
</knoten4>
</knoten1>
Wird „knoten1“ als Knoten-Tag angegeben, können alle Unterknoten in ein Dataframe geschrieben werden. Hierbei bilden die Tags der Ebene 2 die Spalten der Tabelle. Die Werte der hier vorkommenden Tags bilden die Zeilen der Tabelle. Die gesamte Knotenstruktur unterhalb von „knoten4“ wird als Array (Datentyp: struct) in das entsprechende Datenfeld geschrieben. Dies kann auch für mehr als eine Unterebene umgesetzt werden.
In folgendem Beispiel werden alle Unterknoten unterhalb des Tags „knoten1“ ausgelesen, option(„rowTag“,““) definiert dabei den auszulesenden Knoten:

Die Spalte „knoten4“ des Dataframes enthält ein Array anstelle von einzelnen Werten. Die Werte des Arrays können folgendermaßen in separate Spalten geschrieben werden:

Der gefilterte Datensatz wird als neues Dataframe abgespeichert, um später auf den Grunddatensatz zugreifen zu können.
Mit select() ist es auch möglich auf einzelne Unterelemente eines Arrays zuzugreifen und die Spalten des Dataframes wie gewünscht auf relevante Daten einzuschränken:

Analog zur Auslese der CSV-Dateien kann das Dataframe auch für XML-Dateien in eine Delta-Tabelle geschrieben und mit einem SQL-Statement ausgelesen werden.
Datenverarbeitung mit SQL und Python
In Databricks kann SQL verwenden werden, um auf Daten zuzugreifen und diese zu verarbeiten. Es können Daten abgefragt, eingefügt, aktualisiert und gelöscht sowie komplexe Datenbankstrukturen erstellt und verwaltet werden. Gleichzeitig kann Python genutzt werden, um komplexe Analysen und Datenverarbeitungen durchzuführen und zu automatisieren.
Beispiel: Verarbeitung der Daten aus der Beispiel-CSV-Datei
Datenabfrage mit SQL:

Datenabfrage mit Python:
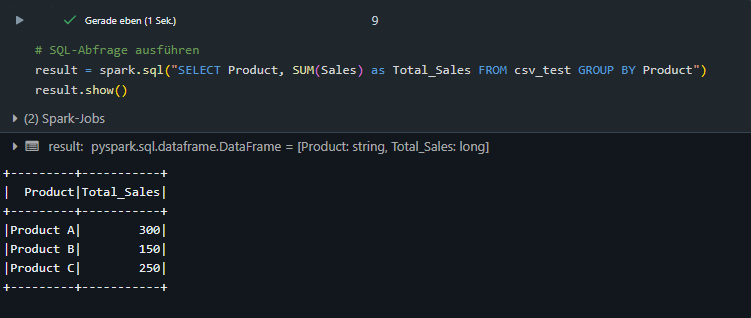
Mit Databricks können SQL-Abfragen direkt im Notebook ausgeführt und die Ergebnisse in Python weiterverarbeiten werden. Dies ermöglicht eine nahtlose Integration beider Technologien.
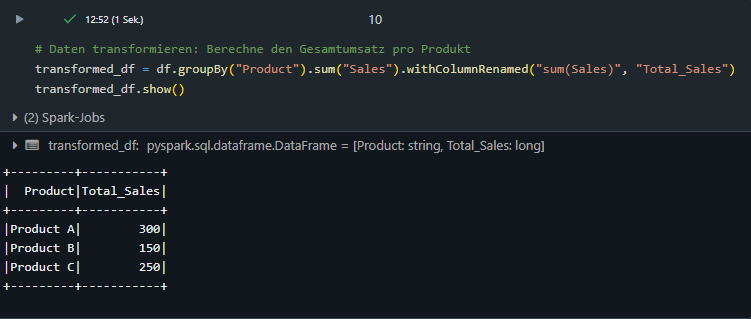
Mit where() oder filter() können Datensätze gefiltert werden. Die Logik ist analog zu einem WHERE-Befehl in einem SQL-Statement.

Mit withColumnRenamed() können Spalten umbenannt werden. Hier wird die Änderung auf das gefilterte Dataframe angewendet und wieder als neues Dataframe abgespeichert.

Automatisierung von Datenpipelines
Zusätzlich zur reinen Datenverarbeitung ermöglicht Databricks die Erstellung und Automatisierung von Datenpipelines, die SQL und Python kombinieren. Dies ist besonders nützlich für ETL-Prozesse (Extract, Transform, Load):
- Extrahieren von Daten mit SQL
- Transformieren der Daten mit Python
- Laden der transformierten Daten in eine neue Tabelle
Fazit
Die Kombination von SQL und Python in Databricks bietet eine wirksame Methode zur Verwaltung und Analyse von Daten. SQL ermöglicht den effizienten Zugriff auf Daten in relationalen Datenbanken, während Python flexible und vielseitige Werkzeuge für die Datenverarbeitung und -analyse bereitstellt. Durch die Integration beider Technologien in Databricks lassen sich robuste und skalierbare Datenlösungen entwickeln, die den Anforderungen moderner Anwendungen gerecht werden.
Für weitere Blogbeiträge schauen Sie gerne auf unserer Website vorbei.

