Die Problemstellung: Einlesen von Daten aus einer OData-Quelle in Talend
Bei der Zusammenführung unterschiedlicher Datenquellen zur weiteren Verarbeitung mittels Talend stößt man auch auf Daten, die man mithilfe eines Webservice abrufen kann. Hierzu gehören z.B. unter anderem OData-Schnittstellen. Bei OData handelt es sich um einen Standard für REST-Webschnittstellen.
Zur Kommunikation mit REST-Webservices existiert in Talend z.B. die tREST Komponente. Um hier aber die Authentifizierung korrekt durchzuführen (stellen Sie sich z.B. vor, ihr Internetverkehr muss über einen Proxy laufen, der auf die Authentifizierung via NTLM Wert legt), die gewünschten Daten aus der XML-Antwort auszulesen oder Daten nur blockweise vom Webservice abzufragen, benötigt man mit tREST einige weitere Schritte bei der Erstellung eines Jobs, vor allem bei der Anbindung mehrerer, unterschiedlicher OData-Quellen.
Der Ansatz: Auslese von OData-Quellen mit Java
Eine weitere mögliche Lösung zur Anbindung von OData-Quellen stellt die Verwendung der Apache Olingo Bibliothek dar. Diese bringt mehrere komfortable Klassen und Methoden mit. Sie bietet zum Beispiel die Möglichkeit, Objekteigenschaften in primitive und nicht-primitive Werte einzuteilen und Anfragen mittels top, skip oder select Kommandos zu strukturieren. Es kann auch eine passender Java-Datentyp zu einer Eigenschaft aus den Metadaten des OData-Services mithilfe des Tools bestimmt werden.
Da Talend mit seinen Routinen bereits eine einfache Möglichkeit bietet, eigenen Java Code in Projekte einzubinden, kann die Olingo Bibliothek leicht in einen Talendjob integriert werden. Dabei bietet sich die Verwendung einer tJavaFlex Komponente an. Der Code in dieser Komponente und der Routine kann in weiten Teilen für unterschiedliche OData-Quellen wiederverwendet werden. Die einzigen Informationen, die ausgetauscht werden müssen, sind das Schema und der Name der Output-Row der tJavaFlex Komponente.
Die Vorteile der Auslese mit Java
Durch eine derartige Datenabfrage eröffnen sich mehrere interessante Möglichkeiten.
Die Auslese im Beispiel
Im Folgenden soll die Verwendung einer selbstgeschrieben OData-Routine im Talend Studio gezeigt werden. Hierzu wird beispielhaft der öffentlich verfügbare OData-Service des U.S. Department of Transportation verwendet. Hier wollen wir das „Railroad Operations Data“-Datenset auslesen.
1. Durch Prüfung des Servicedokuments und der Metadaten sehen wir, dass mit „q3zc-9e5e“ sowohl eine Entity (diese kann man sich als „Eintragstyp“ vorstellen; sie zeigt uns unser Schema) als auch eine Collection, die „Railroad Operations Data“ benannt ist.


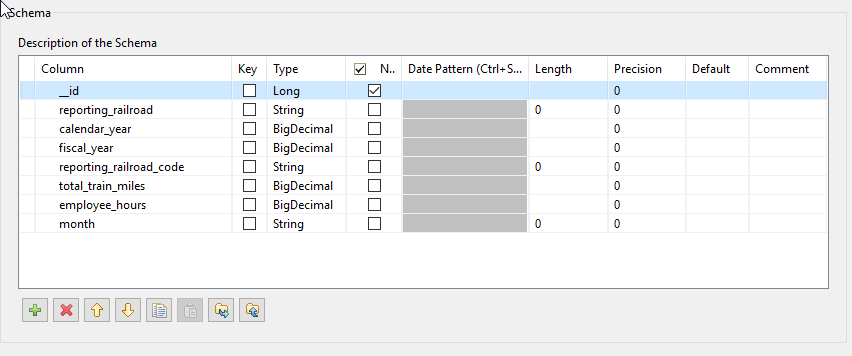
2. Im Talend Studio legen wir nun ein generisches Schema an, welches zur gerade untersuchten Entity passt. Hierbei müssen wir die passenden Java-Datentypen wählen (ein Int64 wird zu einem Long, ein Decimal zu einem BigDecimal, etc.).
3. Anschließen können wir beginnen, unseren Job zu erstellen. Zur Verbindung mit dem OData-Service benötigen wir einige Variablen, die wir hier im Context des Talendjobs anlegen.

Den namespace finden wir im Metadaten-Dokument, die anderen Variablen wurden bereits erklärt. Nutzer und Passwort müssen nicht gesetzt werden, da der Service keine Zugangsdaten verlangt.
4. Mit der von uns erstellten Routine ODataReadout ist es nun relativ einfach möglich, eine grundlegende Auslese der OData-Quelle zu realisieren.

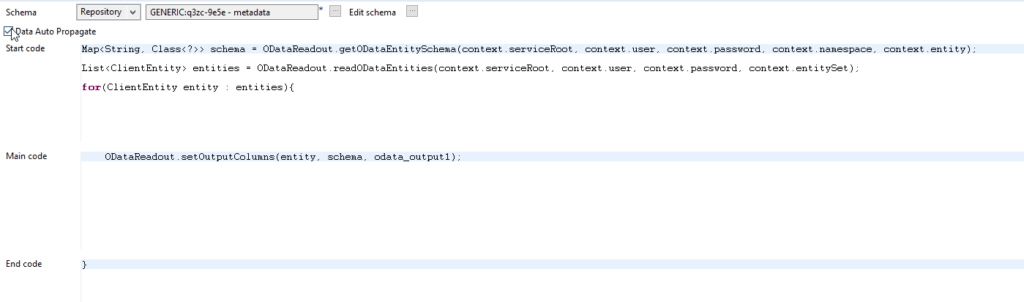
Hierzu benötigen wir nur eine tJavaFlex Komponente. Dieser weisen wir das gerade erstellte Schema zu. Im Start code Block lesen wir zuerst das Schema der Einträge als Map aus. Diese enthält nun den „Spaltennamen“ und den zugehörigen Datentyp bzw. die zugehörige Klasse. Anschließend lesen wir die Entities aus, die der OData-Service zurückgibt. Für jede Entity schreiben wir dann im Main code Block die Eigenschaften (die „Werte“ bzw. die Einträge in den entsprechenden Spalten) einer Entity mit zum Schema passenden Datentypen (die unserem angelegten, generischen Schema entsprechen) auf die Output-Row der Komponente.
5. Zu einem ersten Test verbinden wir die Komponente nun mit einer tLogRow und können uns so die ausgelesenen Werte anzeigen lassen.


Untersucht man den verwendeten Webservice genauer, stellt man fest, dass dieser nicht nur 1000 Einträge hat, wie man nach unserem Test vermuten könnte. Die Antwort des Services auf unseren Request wird allerdings vom Server standardmäßig beschnitten. Auch für dieses Problem gibt es aber eine simple Lösung mithilfe unserer Routine.
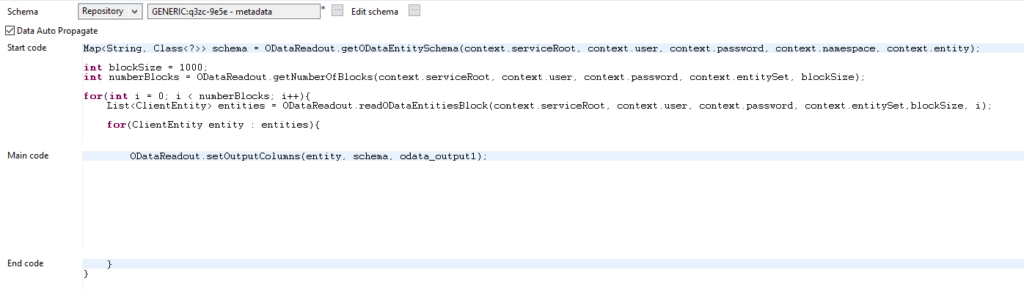
6. Wir zerlegen dazu unsere Anfrage in mehrere einzelne Anfragen, die immer nur einen Teil der Information abrufen. Ein angenehmer Nebeneffekt dieser Art von Auslese ist dabei außerdem, dass wir die zuerst ausgelesen Einträge direkt weiterverarbeiten (z.B. in eine Datei oder Datenbank schreiben) können, während die nächsten noch geladen werden. Hierzu benötigen wir ein paar Anpassungen im Code der tJavaFlex Komponente. Zuerst legen wir eine blockSize fest. Diese entspricht der Anzahl Einträge, die in einem Aufruf abgerufen werden sollen. Anschließend können wir (mithilfe des Wissens über die Gesamtzahl an Einträgen) ausrechnen, wie viele Blöcke in Größe der blockSize wir auslesen müssen. Durch eine weitere for-Schleife können wir nun das zuvor implementierte Auslesen blockweise realisieren.
7. Eine Ausführung unseres Jobs (statt die tLogRow zu verwenden, schreiben wir die Daten nun in eine csv-Datei, um die Konsolen-Anzeige nicht zu überlasten) zeigt uns, dass unser Job mit blockweiser Auslese auch für große Datenmengen gut funktioniert.



Ein Blick in unsere Ausgabedatei (und auf die dort gespeicherten IDs) zeigt uns außerdem, dass die Daten vollständig geladen wurden.


Wir konnten so also erfolgreich demonstrieren, dass auch OData-Services als Datenquelle für Talend dienen können und weiterhin zeigen, dass es sinnvoll sein kann, die einfache Bedienbarkeit von Talend mit der Mächtigkeit und Flexibilität von speziell geschriebenem Javacode zu kombinieren, z.B. im Hinblick auf die blockweise Auslese einer Datenquelle oder die erweiterte Konfiguration einer http-Verbindung.

