Die Drei-Schichten-Architektur beschreibt das Konzept, eine Software-Lösung in drei Schritte zu unterteilen: In Präsentationsschicht, Logikschicht und Datenhaltungsschicht. Die oberste Schicht ist hierbei für die Präsentation und Nutzerinteraktion gedacht. Diese kann z.B. durch einen Jasper-Report realisiert werden. Im Gegensatz dazu stellt die unterste Schicht (Datenhaltungsschicht) die Rohdaten dar, die in den Jasper-Report einfließen, z.B. Verkaufsdaten in einer Tabelle in einer Datenbank.
In diesem Beitrag betrachte ich die mittlere Schicht (Logikschicht) einmal genauer. Diese Ebene beschreibt die Verarbeitung der Rohdaten (z.B. Selektion und Verrechnung), bevor diese angezeigt werden. Für diesen Schritt kann der Anwender eine Datenabfrage bei der Erstellung eines Jasper-Reports im Jaspersoft Studio konfigurieren. Es ist allerdings von Vorteil, diese Logik-Schicht unabhängig vom eigentlichen Reporting zu halten, beispielsweise, wenn die gleiche Berechnungs-Logik für mehrere Berichte verwendet wird oder die Verantwortlichen für Berechnungen und Report-Design unterschiedliche Personen sind. Hierfür wird im Folgenden eine mögliche Lösung skizziert.
Die Idee: Auslagern der Logik-Schicht in eine View
Die Trennung der Logik der Datenselektion vom Report an sich scheint keine größere Herausforderung darzustellen. Ein select-Statement lässt sich in einer View (oder, je nach Anwendungszweck, sogar einer materialized View für bessere Performance) ablegen. Im Jasper-Report muss dann nur noch aus dieser View selektiert werden.


Die Herausforderung: Nutzung verschiedener Views in Test- und Produktivsystem
Wenn nun ein Test- und ein Produktiv-Jasperserver vorhanden sind, stellt einen die Auslagerung der Logik-Schicht gegebenenfalls vor Probleme. Mit dem Test- und Produktiv-Jasperserver möchte man vor allem die Datenanzeige und Logik innerhalb des Jasper-Reports testen, aber nicht mehr die Datenselektion, die man ja nun extra vom Bericht separiert hat. Was passiert aber, wenn sich die Datenabfrage gleichzeitig mit dem Bericht ändern soll? Es ist beispielsweise möglich, dass ein Feld weniger selektiert werden soll, da nach anderen Feldern gruppiert wird. Hierfür müssten sowohl der Bericht als auch die View angepasst werden. Wenn die gleiche View allerdings auf dem Test- und Produktivserver zur Datenselektion verwendet wird, läuft man Gefahr, durch Anpassungen für das Testsystem den produktiven Bericht zu beeinflussen. Legt man allerdings eine neue View für Änderungen im Test-Bericht an, so muss man den Namen der View auch bei kleineren Änderungen immer im Test- und anschließend im produktiven Bericht austauschen. Die angestrebte Trennung von Logik-Schicht und Präsentations-Schicht liegt dann faktisch nicht mehr vor.

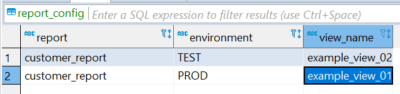
Die Lösung: Pflegen einer Konfigurationstabelle mit View-Namen
Abhilfe kann hier eine Konfigurationstabelle schaffen, in der für den Test- und Produktiv-Bericht unterschiedliche View-Namen hinterlegt werden können. So kann für größere Änderungen an der Datenselektion eine neue View erstellt werden, deren Name dann in der Konfiguration für den (bearbeiteten) Test-Bericht hinterlegt wird. Sind alle Änderungen an View und Bericht am Test-Server erfolgreich geprüft worden, kann der View-Name auch als Konfiguration für den Produktiv-Server gesetzt werden und der Bericht dort ausgetauscht werden. Bei kleineren Änderungen an der Datenselektion dagegen reicht es aus, eine neue View anzulegen, und diese nach erfolgreichem Test auch als View für den produktiven Bericht einzutragen. Der Bericht selbst muss dann nicht mehr bearbeitet werden.
Die Umsetzung: Aufruf des Jasper-Berichts durch ein Workbook
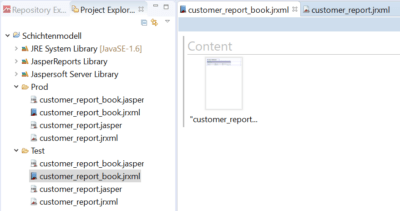
Um den Abruf der Daten im Bericht aus der korrekten View zu ermöglichen, erstellt man für diesen Bericht ein Workbook. Dieses enthält einen Parameter mit der Information, ob es sich um einen Bericht auf dem Test- oder dem Produktiv-System handelt. Der eigentliche Bericht wird im Content-Band des Workbooks hinterlegt.
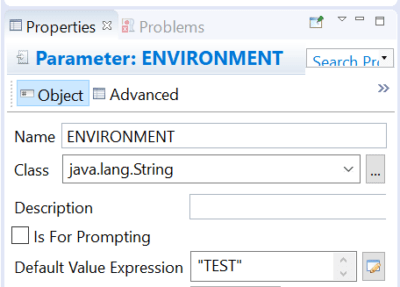
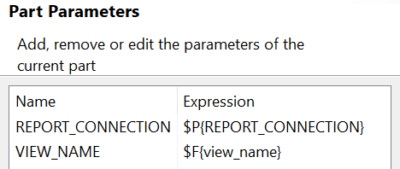
In der Query des Workbooks selektiert der Anwender damit nun den korrekten Namen der View für den Bericht, welchen man wiederrum als Parameter an den Bericht weiterreichen kann. Im Bericht selektiert man anschließend mit der $P!-Syntax aus der View.


Der Bericht wird fortan nur noch über das Workbook abgerufen, welches man in unterschiedlicher Konfiguration auf Produktiv- und Testsystem ablegt. Wird in Zukunft die Berichts-Jrxml-Datei überarbeitet, so ist nur diese auszutauschen, das Workbook kann unangetastet gelassen werden. So bleibt sichergestellt, dass immer die korrekte View im Bericht verwendet wird.
Der Vorteil: Die Trennung von Abfrage und Anzeige
Durch dieses Vorgehen wird eine Trennung von Datenabfrage und -anzeige ermöglicht. Damit lässt sich auch die Verantwortung für die beiden Aufgaben aufteilen, so dass der Berichts-Designer nicht mehr alle Informationen über die unterliegende Datenstruktur braucht, während sich der Query-Designer nicht mehr mit dem Design der Ausgabe beschäftigen muss. Im Gegensatz zu einer direkt im Bericht hinterlegten Abfrage ist es außerdem möglich, die Änderungen an der Datenabfrage zu bearbeiten, nachdem das Berichtsdesign bereits angepasst wurde. Je nach anzuzeigenden Daten lässt sich die Berichtserstellung durch die Nutzung von materialized Views gegebenenfalls sogar beschleunigen.

