Überblick
Künstliche Intelligenz (KI) gewinnt zunehmend an gesellschaftlicher Bedeutung und ist aktuell in aller Munde. ChatGPT gibt die „Macht“ der künstlichen Intelligenz in die Hände der breiten Bevölkerung. Ob das nun als gut oder schlecht zu bewerten ist, daran scheiden sich die Geister. Die einen stürzen sich in neue Arbeitsmethoden, während andere, unter ihnen auch Tech-Gigant Elon Musk, einen Trainingsstopp für KI fordern. Was also hat es mit diesen KI-Modellen auf sich? Was ist das Besondere an ihnen? Diese Fragen werden im Rahmen dieses Blogeintrags beantwortet. Im zweiten Teil dieser Blog-Serie wird die Intelligenz dieser KI betrachtet und auf die Fragestellung eingegangen, inwiefern sich diese von der Intelligenz von Menschen unterscheidet.
Warum ist KI aktuell ein so heißes Thema?
Künstliche Intelligenz ist ein breites Feld, an dem seit Jahrzehnten geforscht wird. Selbstlernende Algorithmen sagen schon lange Systemausfälle voraus, fahren Auto oder diagnostizieren Krankheiten in CT-Bildern. Warum sind sie also gerade jetzt ein so großes Thema? Viele Menschen, die von KI oder AI (Artificial Intelligence) sprechen, meinen eigentlich „KAI“ (AGI): Künstliche Allgemeine Intelligenz (Artificial General Intelligence). Ein lernfähiges Computerprogramm, das ähnlich intelligent oder sogar deutlich intelligenter ist als ein Mensch.
Large Language Models (LLM) wie ChatGPT wirken wie ein erster Schritt in diese Richtung. Ein Computer, der natürliche Sprache versteht und genau das ausführt, was ihm vermittelt wird. Tatsächlich revolutionieren LLMs die Interaktion zwischen Menschen und Computern. Menschen ohne technisches Wissen können mit Hilfe der KI und Anweisungen in natürlicher Sprache komplexe Programme verwenden und komplizierte Aufgaben erledigen.
Was sind LLMs?
Pre-trained Language Models (PLM) sind der aktuelle Stand der Technik im Bereich der Sprachverarbeitung. Diese Art von neuronalen Netzen wird auf großen Text Corpora „vor-trainiert“ (pre-trained), bevor das Modell auf allgemeines Textverständnis abgestimmt (fine-tuned) wird. PLMs sind also KI-Modelle, die in erster Linie darauf trainiert sind, Sprache zu verstehen. LLMs sind sehr große PLMs mit zehn bis mehreren hunderten Milliarden Parametern. GPT-3, das Modell hinter ChatGPT, besitzt beispielsweise 175 Milliarden Parameter – PaLM, ein LLM von Google ganze 540 Milliarden. Das aktuell größte LLM, GPT-4, soll bis zu 100 Billionen Parameter besitzen und kommt damit an die Komplexität des menschlichen Gehirns heran. Denn die Anzahl der Parameter von neuronalen Netzen kann mit der Anzahl der Synapsen im menschlichen Gehirn verglichen werden. Unser Gehirn besteht aus ca. 86 Milliarden Neuronen mit schätzungsweise 100 Billionen Synapsen.
LLMs funktionieren jedoch anders als das menschliche Gehirn. Bei der Erstellung eines Satzes wird ein Wort nach dem anderen generiert. Für jedes neue Wort wird die Wichtigkeit jedes vorherigen Wortes berechnet. Schlagworte können „im Gedächtnis“ des Modells gehalten werden. So entstehen semantisch passende Antworten. Außerdem wird die Struktur des Satzes in die Vorhersage des nächsten Wortes besser mit einbezogen, was zu grammatikalisch korrekten Lösungen führt.
Was ist das Besondere an LLMs?
Wie bereits erwähnt revolutionieren LLMs die Interaktion zwischen Menschen und Computern. Sie werden durch natürliche Sprache bedient und können somit auch sehr komplexe Anweisungen entgegennehmen.
Außerdem kann die KI argumentieren, kausale und mathematische Zusammenhänge – wenn auch mit Einschränkungen – herleiten, Code schreiben und andere „kreative“ Lösungen erzeugen. Diese generalistischen Fähigkeiten werden „Emergent Abilities“ genannt, denn sie gehen über das hinaus, worauf die KI trainiert wurde. Durch diese Fähigkeiten passen sich die Modelle sehr genau an die Anforderungen des individuellen Benutzers an und wirken intelligent. Die Emergent Abilities treten ab einer Größe von ca. 100 Milliarden Parametern auf.

Abbildung 1: Beispiel für Few-Shot Learning, einer Prompting Taktik
Um eine hohe Genauigkeit der Antworten zu erreichen, gibt es verschiedene Eingabetaktiken, was als Prompt-Engineering bezeichnet wird. Man erstellt also speziell abgestimmte Anweisungen für das LLM. In Abbildung 1 ist das sogenannte Few-Shot Learning dargestellt. Anhand weniger Beispiele in der Eingabe versteht das LLM wie es die Aufgabe zu lösen hat. In Abbildung 2 sind die Vorteile des Chain-of-Thought Promptings dargestellt. Weist man das LLM an, eine Aufgabe mit Zwischenschritten zu lösen, kommt die KI auf deutlich bessere Lösungen als ohne Zwischenschritte.
Das Besondere beim Prompt-Engineering ist, dass das zugrunde liegende Modell und seine Parameter nicht verändert werden. Trotzdem „lernt“ das LLM wie es eine gestellte Aufgabe zu lösen hat, ohne diese vorher schon einmal gesehen zu haben. Das „Lernen“ und Anpassen während der Unterhaltung ist eine der überraschenden Emergent Abilities, die laut einigen Wissenschaftlerinnen und Wissenschaftlern einen Funken Intelligenz darstellt.
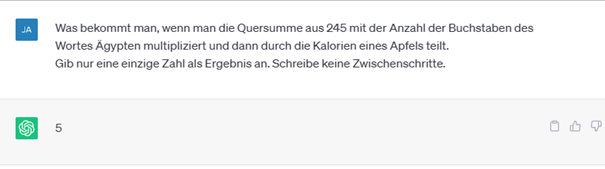
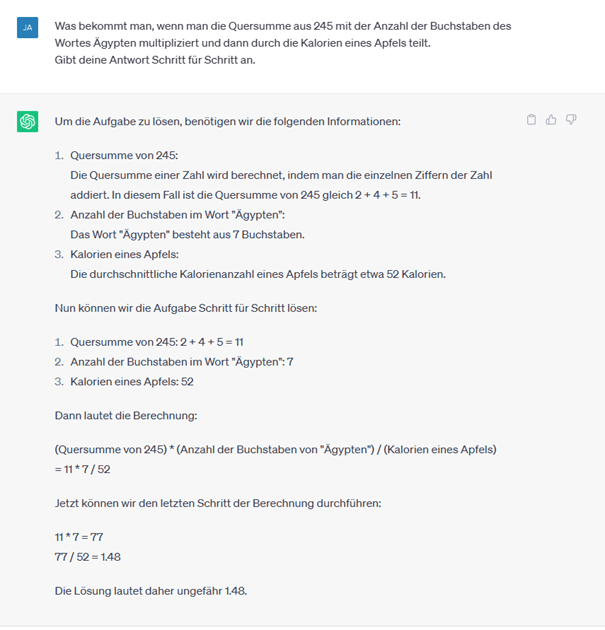
Abbildung 2: Beispiel für die Vorteile eines Chain-of-Tought Prompts. Ohne die Zwischenschritte kann das LLM die Aufgabe nicht lösen.
Im zweiten Teil dieser Blog-Serie wird die Frage nach der Intelligenz von Large Language Modells in den Fokus gestellt. Sind LLMs tatsächlich als intelligent zu betrachten? Inwiefern unterscheidet sich die Intelligenz dieser KI zu der des Menschen? Darüber hinaus werden die aktuellen Probleme, die beispielsweise ChatGPT mit sich bringt, behandelt und darauf aufbauend gezeigt, in welchen Bereichen der Einsatz von LLM nützlich erscheint.

