Einführung
Der Anfang – Warum? Weshalb? Wieso?
DataVault ist in vielen modernen Data Warehouses ein integraler Bestandteil des Datenbankmodells. Erfunden von Dan Linstedt (danlinstedt.com) stellt DataVault die optimale Technik zur agilen Beladung von Datenbanken, vor allem wegen der integrierten Historisierung und der hohen Flexibilität dar.
Schon seit vielen Jahren sind bei PRODATO und deren Kunden Oracle-Datenbanken im Einsatz. Dazu gehörten auch immer die passenden ETL-Tools. Mit der Ablösung des Oracle Warehouse Builders (OWB) durch den Oracle Data Integrator (ODI) boten sich schließlich enorme Möglichkeiten zur Automatisierung und eine feinere Steuerung der Modellierung. Da alte Prozesse auf die neuen Tools migriert werden mussten, wurde hier gleich die Gelegenheit zur teilweisen Umstellung auf DataVault genutzt.
In diesem Beitrag soll gezeigt werden, wie das DataVault-Prinzip in unserem Projekt unter eigenständiger Entwicklung ein Tool hervorgebracht hat, welches Entwicklungsaufwand und -dauer reduziert und Fehler minimiert hat.
DataVault – Basics
DataVault bringt einige Vorteile mit sich, wie z. B. erhöhte Skalierbarkeit durch mögliche Verbesserung der Parallelisierung von Lade-Prozessen und die Historisierung und Nachvollziehbarkeit von Daten.
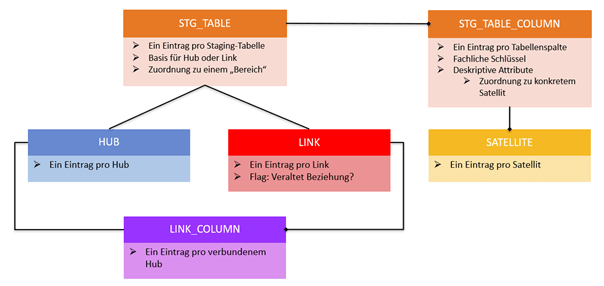
Im Wesentlichen kennt DataVault drei Tabellentypen, welche beladen werden:
- Hubs: enthält eine Liste der Business Keys, Surrogatschlüssel sind als Zahl (ID, in DataVault 1.0) oder HashKey (DataVault 2.0) gespeichert
- Links: Abbildung der Beziehung zwischen zwei oder mehr Hubs.
- Satellites: Speicherung der deskriptiven Attribute, hier passiert die eigentliche Historisierung, da bei geänderten Quelldaten ein neuer Eintrag gespeichert wird. Hubs und Links können jeweils mehrere Satellites besitzen.
Durch dieses einheitliche Schema und die vereinheitliche Ladelogik, ist es fast schon notwendig Codegenerierung zu verwenden. Daher wird in allen Data Warehouses, welche DataVault verwenden, irgendeine Form von Codegenerierung verwendet, meistens durch spezialisierte Software, welche zugekauft wird.
Beispiel für ein DataVault-Modell:

Codegenerierung
Wie bereits erwähnt, ist es sehr sinnvoll, bzw. notwendig, Codegenerierung für die Nutzung von DataVault zu verwenden.
In unserem Projekt sollte aber keine Software hinzugekauft werden, sondern eine eigene Version eines Generators geschrieben und implementiert werden. Die Grundvoraussetzungen existierten bereits: Der ODI wurde im Projekt schon verwendet, große Teile der Software des Projekts sind in Java geschrieben und über die ODI API ließ sich beides nahtlos verbinden, da diese API ebenfalls Java bzw. Groovy verwendet.
Außerdem gab es eine spezielle Anforderung an „unser“ DataVault: Wie bereits erwähnt, konnten einige Faktentabellen nicht migriert werden. Um also trotzdem die Kompatibilität zwischen alt und neu zu gewährleisten musste hier eine Mischform des DataVault verwendet werden, wo zwar bereits HashKeys als Surrogatschlüssel verwendet werden konnten, zusätzlich aber noch die alten Surrogat-IDs gespeichert werden mussten, welche Stammdaten und Fakten verbinden.
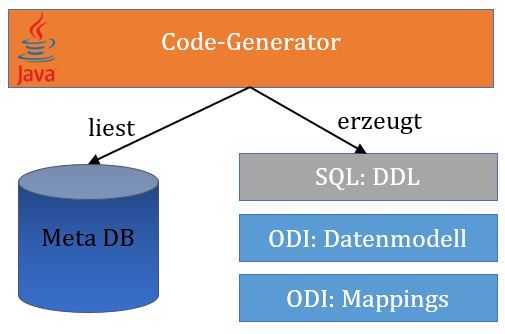
Das Meta-Modell in der Datenbank
Um dem Generator einheitlich mitzuteilen, wie Datenmodell und Mappings generiert und welche Quellobjekte und -spalten in welche DataVault-Objekte geladen werden sollen, ist ein Metadatenmodell notwendig.
In diesem Modell wurden die folgenden Pflegetabellen erstellt:
- STG_TABLE: Dort wird für jede Tabelle aus der Staging-Area ein Eintrag geschrieben. Außerdem ist es möglich mehrere Staging-Tabellen zu einem Bereich, bei uns „Theme“ genannt zusammenzufassen, um so mehrere DataVault-Objekte und Mappings auf einmal generieren zu können, welche thematisch zusammengehören. Beispiel wäre hier die Beladung aller Artikelbezogenen Tabellen in einem Ladeprozess.
- STG_TABLE_COLUMN: Für jeden STG_TABLE-Eintrag existieren ein oder mehrere STG_TABLE_COLUMN-Einträge – für jede Quellspalte einer. In dieser Tabelle wird auch gepflegt, bei welchen Spalten es sich um fachliche Schlüssel oder rein deskriptive Attribute handelt. Außerdem kann der Ziel-Satellite hier festgelegt werden. Das ist z.B. hilfreich, wenn zusätzliche Attribute hinzukommen, welche in einen separaten Satellite geschrieben werden sollen.
- HUB: Hier sind hauptsächlich die Bezeichner der Hubs enthalten, für die es pro Hub wieder jeweils nur einen Eintrag gibt.
- LINK: Analog zu HUB sind hier die Bezeichner der Links enthalten. Zusätzlich wird hier aber noch die Information gepflegt, ob eine Beziehung veralten, sprich ungültig werden kann, z. B. Der Link zwischen Kunde und Adresse. Pro Link existiert ebenfalls wieder ein Eintrag.
- LINK_COLUMN: In dieser Tabelle wird schließlich gepflegt, welche Hubs durch einen Link verbunden über welche Spalten werden. Hier muss für jeden so verbundenen Hub und Link ein Eintrag geschrieben werden.
Java-Code
Bibliotheken und Properties
Zur Verwendung der ODI-Funktionen im Java-Code wurden die entsprechenden Libraries eingebunden, welche im Installationsverzeichnis des ODI zu finden sind. Hier ist vor allem die Library odi-core.jar wichtig, die die Basisfunktionen beinhaltet. Außerdem ist odi-sdk-invocation.jar essenziell, um die ODI SDK API verwenden zu können. Insgesamt wurden hier aber aufgrund von Abhängigkeiten und weiteren Funktionalitäten 32 Libraries eingebunden.
Um den Generator steuern zu können, wurde für jedes Thema eine eigene Properties-Datei angelegt. Ein Thema bedeutet hier: Eine thematisch zusammenhängende Menge von zu generierenden Objekten. Ein Beispiel wäre hier Produkte, wobei hier der Produkt-Hub, aber auch der Produkt-Satellite, sowie weitere Links und Satellites zu Einkaufs- und Verkaufspreisen, Steuern, Zuordnungen zu Lagern usw. enthalten sind. Bei einer Änderung an einem Objekt kann so gezielt die Struktur des gesamten Produkt-Themas und die zugehörigen Prozesse neu erstellt werden. So ist sichergestellt, dass der jeweilige Prozess immer in sich konsistent bleibt.
In diesen Properties-Dateien werden Informationen, wie das Ziel-Schema in der Datenbank, der zu verwendende Tablespace und der Projektordner im ODI, aber auch kosmetische Einstellungen wie Prä- und Suffixe, Kürzel zur besseren Lesbarkeit usw. festgelegt.
Anfangs wurden diese Properties noch für jedes Thema einzeln händisch angelegt, mittlerweile ist dies aber über eine UI erstell- und editierbar.
Code-Aufbau
Der Java-Code ist recht simpel gehalten. Im Kern sind Klassen für alle Objekte wie Hubs, Satellites, Spalten, usw. enthalten. Außerdem werden hier die Funktionen zur Erstellung der Datenbank-Skripte und ODI-Prozesse aufgerufen. Hier kann auch eine Generierung simuliert werden, d.h. in der Konsole wird ausgegeben, welche Objekte der Generator anlegen würde und wie die entsprechenden Skripte aussehen würden. Dies war vor allem am Anfang zu Debug-Zwecken sehr hilfreich.
Hier kann auch gesteuert werden, ob entweder nur die Datenbank-Skripte oder die ODI-Prozesse oder beides generiert werden sollen und ob DataVault 2.0 oder unser hybrider DataVault-1.0-Ansatz aus Legacy-Gründen werdet werden soll.
Die erstellten Datenbank-Skripte sind so einfach wie möglich gehalten, d.h. es werden einfache „CREATE TABLE XYZ ( )“ – Statements erstellt. Die in den Meta-Daten gepflegten fachlichen Schlüssel und multiaktiven Attribute werden hier zur Erstellung von Primary und Unique Keys verwendet. Dies vereinfacht im nächsten Schritt die Erstellung der ODI-Mappings.
Bei der Erstellung der ODI-Objekte und -Mappings wird ebenfalls auf Meta-Daten und Properties zurückgegriffen. Prinzipiell werden die Objekte analog zu den Tabellen in den Datenbank-Skripten angelegt. Die Mappings selbst sind sehr einfach aufgebaut, da die eigentliche Funktionalität in den verwendeten Knowledge Modulen enthalten ist. Auf die verwendeten Knowledge Module wird im nächsten Abschnitt nochmals genauer eingegangen.
Beim Start des Generators werden die gepflegten Properties eingelesen, bei neuen Themen wird ein Template verwendet, welches bereits grundsätzliche Einstellungen beinhaltet. Dann wird ausgewählt welche DataVault-Version verwendet werden soll. Anschließend werden entsprechend der Properties-Datei und gepflegten Meta-Daten die Datenbank-Skripte erstellt und als .sql-Datei abgelegt. Daraufhin werden die ODI-Objekte, -Mappings und -Prozesse erstellt. Ist die Generierung abgeschlossen und die Skripte auf der Datenbank ausgeführt, ist der entsprechende ODI-Prozess bereits lauffähig und zum Testen bereit.
ODI
Flexfelder
In den generierten Mappings werden mehrere Flexfelder verwendet.
Flexfelder sind eine Funktion des ODI, wodurch an jedem Objekt, also Spalte, Datentyp, Tabelle, Schema oder sogar an Datenbankverbindungen zusätzliche Informationen gespeichert werden können.
Da bei der Erzeugung eines Hash-Wertes auch der zugrundeliegende Datentyp Auswirkungen hat, werden für alle Spalten im ODI entsprechende Flexfelder angelegt. Hierdurch werden alle Datentypen wie Numeric, Date, usw. explizit in einen String konvertiert. Die hierfür benötigten Flexfelder sind für Präfix und Suffix der Konvertierung.
Beispiel: Alle Date-Spalten erhalten als Präfix „TO_CHAR(“ und den Suffix „, ‘dd.mm.yyyy‘)“. Dadurch werden immer alle Datum-Felder auf die gleiche Weise in einen String konvertiert.
Des Weiteren wird für jeden Hub und Link ein Flexfeld verwendet, um die Eindeutigkeit von Hashes zu gewährleisten und so Hashkollisionen zu verhindern. Dazu wird in dieses Flexfeld der Name des Hubs bzw. Links geschrieben und zusätzlich zu den Business Keys zur Berechnung des Hashes verwendet.
Knowledge Module
Als Basis für die Knowledge Module werden die bereits mitgelieferten Module des ODI verwendet und angepasst.
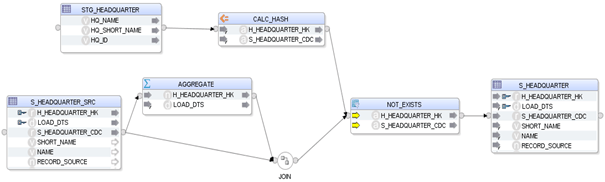
Beispiel eines Mappings ohne angepasstes Knowledge Module:
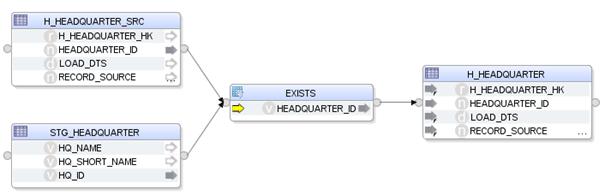
Hierbei wird der HEADQUARTER-Hub mit den HEADQUARTERs aus der Quelle gejoint und somit neue Einträge ermittelt. Allerdings ist man durch die jeweils verwendeten Business Keys nicht sehr flexibel und es müsste in diesem Fall jedes Mal die EXISTS-Komponente dynamisch angepasst werden.
Eine einfachere Möglichkeit ist die Anpassung des Knowledge Modules, so dass das Mapping dann wie folgt aussieht:
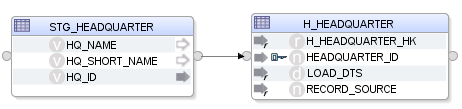
Der Code des Knowledge Modules ersetzt diese Ermittlung der nichtexistierenden Business Keys:
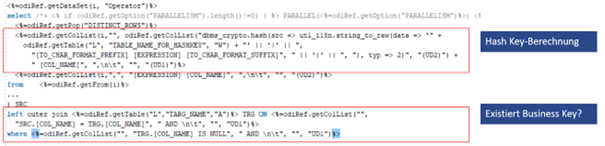
Durch den Generator werden die verwendeten Flexfelder „TABLE_NAME_FOR_HASHKEY“, „TO_CHAR_FORMAT_PREFIX“, usw. bereits vor der Generierung gepflegt und können hier dynamisch ausgelesen und durch das Knowledge Module verwendet werden.
Eine weitere Besonderheit des ODI sind die User Definded Flags (in diesem Fall UD1 und UD2), wobei hier Surrogate bzw. Hash Keys das Flag UD1 und Business Keys das Flag UD2 erhalten. Mittels dieser Flags können innerhalb des Knowledge Module, Codes Spalten gefiltert werden.
Im Beispiel oben wurde ein Mapping für eine Hub-Beladung gezeigt. Der Unterschied bei der Beladung eines Satellites ist aber nochmal deutlicher. Zuerst die Beladung unter Verwendung der Standard-Knowledge Module:
Im Gegensatz dazu die Verwendung des angepassten Knowledge Modules:

Auch hier werden sämtliche Ermittlung neuer Datensätze, sowie die Berechnung von Hash- und CDC-Keys durch das Knowledge Module übernommen:
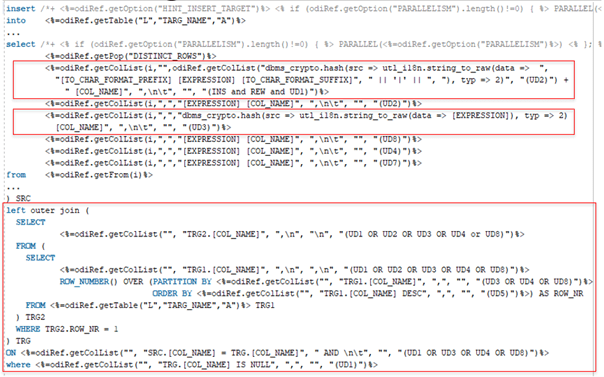
Auch hier werden wieder UD-Flags verwendet: UD1 – CDC HashKey, UD2 – Deskriptive Attribute, UD3 Hub HashKey, UD4 Hub Surrogat-ID (für DV 1.0.), UD5 – LOAD_DATE, UD6 – LOAD_END_DATE, UD7 – Nicht Hash-relevante Attribute, UD8 – Multiaktive Attribute.
Somit kann jeder Spaltentyp genau adressiert werden. Das Flag für nicht hash-relevante Attribute wird beispielsweise für CLOBs verwendet, für eine Hash-Funktion nicht performant ist oder gar nicht funktioniert.
Knowledge Module verwenden die OdiRef Substitution API, wofür eine umfangreiche Dokumentation bei Oracle existiert.
Durch die Verwendung von eigens angepassten Knowledge Modulen konnte die Flexibilität und Übersichtlichkeit der ODI-Mappings deutlich gesteigert werden.
UI und Ausblick
Java FX
Zum Anfang wurde der Generator ausschließlich manuell über das Terminal gesteuert, die Properties und alle Meta-Daten händisch gepflegt und war somit nicht ohne weiteres durch weitere Entwickler verwendbar.
Um das zu ändern, wurde eine UI unter Verwendung von Java FX erstellt. Mittlerweile lässt sich fast sämtliche Funktionalität über diese Oberfläche steuern.
Beispiele:
Auswahl der Properties-Datei:

Auswahl der Quelltabellen, Festlegung der entsprechenden Flags
Mögliche Erweiterung
Der Generator wurde projektspezifisch nur für Oracle-Datenbanken entwickelt. Da der ODI aber auch mit einer Vielzahl anderer Datenbank-Technologien funktioniert, lässt sich der Generator entsprechend erweitern. Somit kann er zukünftig auch für andere Projekte und Technologien zum Einsatz kommen.
Fazit
Die mit DataVault vorangehende Historisierung und Flexibilität waren der ausschlaggebende Grund für die Projekteinführung bei einem führenden deutschen Lebensmitteldiscounter, für den wir von PRODATO bereits seit über 15 Jahren tätig sind.
Die Entwicklung des Generators war ein voller Erfolg. Das Tool wird in der täglichen Entwicklung von mehreren Anwendern verwendet. Dadurch hat sich die Entwicklungszeit von neuen Beladungen um ein Vielfaches beschleunigt. Außerdem lassen sich Änderungen der Anforderungen auf Knopfdruck umsetzen. Entstandene Modellierungsfehler lassen sich ebenso einfach beheben.
Die Entwicklung des Tools konnte durch wenige Entwickler in einigen Wochen neben dem Tagesgeschäft erfolgen, langfristig jedoch einen großen Zeitgewinn und eine gesteigerte Flexibilität zur Folge.
Zusätzlich dazu konnten die Funktionen und Möglichkeiten des ODI besser kennengelernt und verwendet werden. In einer 1:1-Migration vom OWB auf den ODI wäre das nicht in dieser Form erfolgt.
Seit über 15 Jahren verwenden wir bereits Oracle-Datenbanken und -Tools. Zudem sind wir Oracle-Partner und waren mehrfach auf entsprechenden Veranstaltungen und Webinaren vertreten.
Bei Fragen bezüglich Oracle Datenbanken oder dem Oracle Data Integrator stehen wir Ihnen gerne zur Verfügung.

