Übersicht
Kennzahlen (Key Performance Indicators, KPIs) dienen der quantitativen Bewertung der Leistung eines Unternehmens. Datenvirtualisierung ist ein agiler Ansatz, der es ermöglicht, auf Daten aus mehreren Quellen aus einer virtuellen Schicht zuzugreifen und diese in Echtzeit abzufragen, ohne sie physisch replizieren zu müssen. Dieser Beitrag befasst sich mit der Erstellung eines Python-basierten KPI-Dashboards für illustrative Einblicke und Echtzeit-Erkenntnisse durch Daten, die aus einer marktführenden Datenvirtualisierungsplattform, die Data Virtuality, in einheitlichen Views der Business Logik abgebildet werden.
Das Dashboard ermöglicht daher eine fundierte Analyse von KPIs basierend auf Daten, die aus diversen Quell-Systemen (Datenbanken, Dateien) stammen und deren Schemas und Metadaten in die Data Virtuality Plattform extrahiert werden. Business Data Views können anschließend modelliert werden, die nach optimierter Ausführung dem Dashboard-Zielsystem als Datenkatalogprodukte bereitgestellt werden. Das folgende Diagramm veranschaulicht das System:
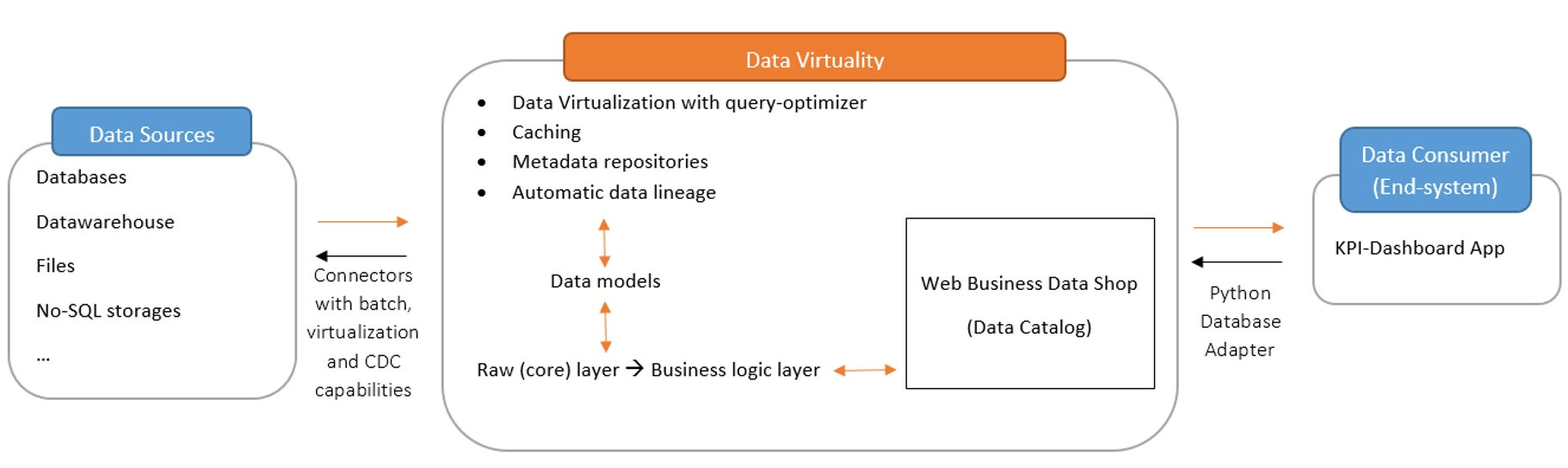
Datenbasis durch Data Virtuality
Data Virtuality stellt eine integrierte Plattform bereit, die Datenvirtualisierungs-, Query-Optimierungs, Caching-, automatische Data Lineage- und Change Data Capture (CDC)-Funktionen vereint. Diese Kombination ermöglicht einen effizienten Datenbereitstellungsprozess in einer einzigen umfassenden Lösung. Informationen zu PRODATOs Technologiepartnerschaft mit Data Virtuality und zu unserem Service finden Sie unter Data Virtuality und PRODATO beschließen Partnerschaft und unter Data Virtuality.
Die vom KPI-Dashboard analysierten Daten wurden erst durch die Data Virtuality Plattform erfasst. Dafür wurde eine Software-as-a-Service (SaaS)-Deployment der Data Virtuality Plattform für schnelle Umsetzung verwendet. Das benutzerfreundliche Web User Interface (UI) gibt einen Überblick über die Plattform und deren Status:
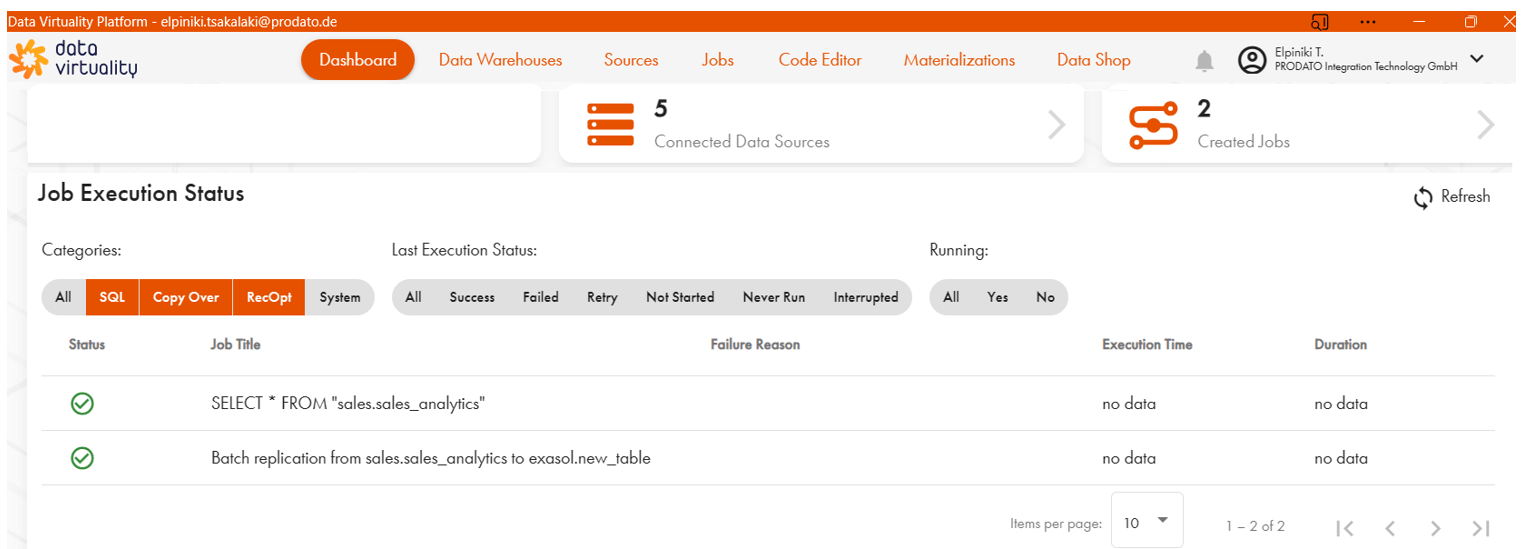
Anbindung von Datenquellen
Die angezeigte Plattform enthält 5 Datenquellen. Für den KPI-Dashboard werden Daten aus 3 davon benötigt: aus mysql (MySQL), pgsql (PostgreSQL) und aus google_spreadsheets (Google Sheets).
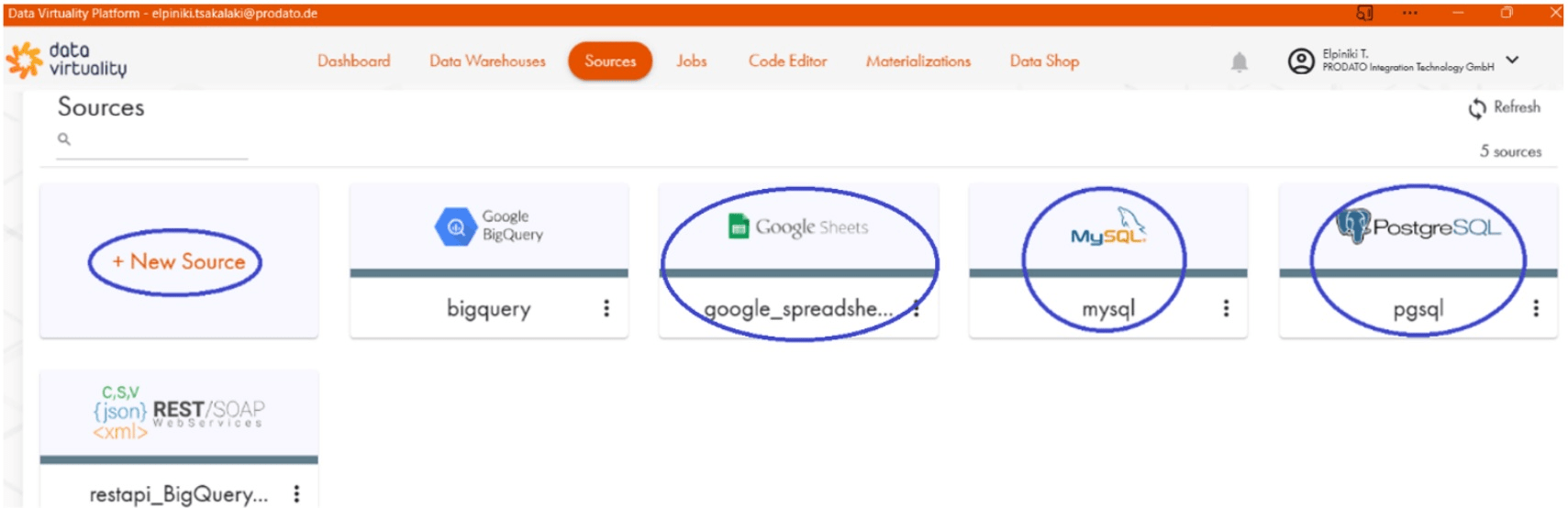
Die Datenquellen wurden auf Sources → +New Source angebunden. Alternativ können sie mittels des speziellen Stored Procedure createConnection des Built-in Schemas SYSADMIN verbunden werden.
Erstellung virtueller View
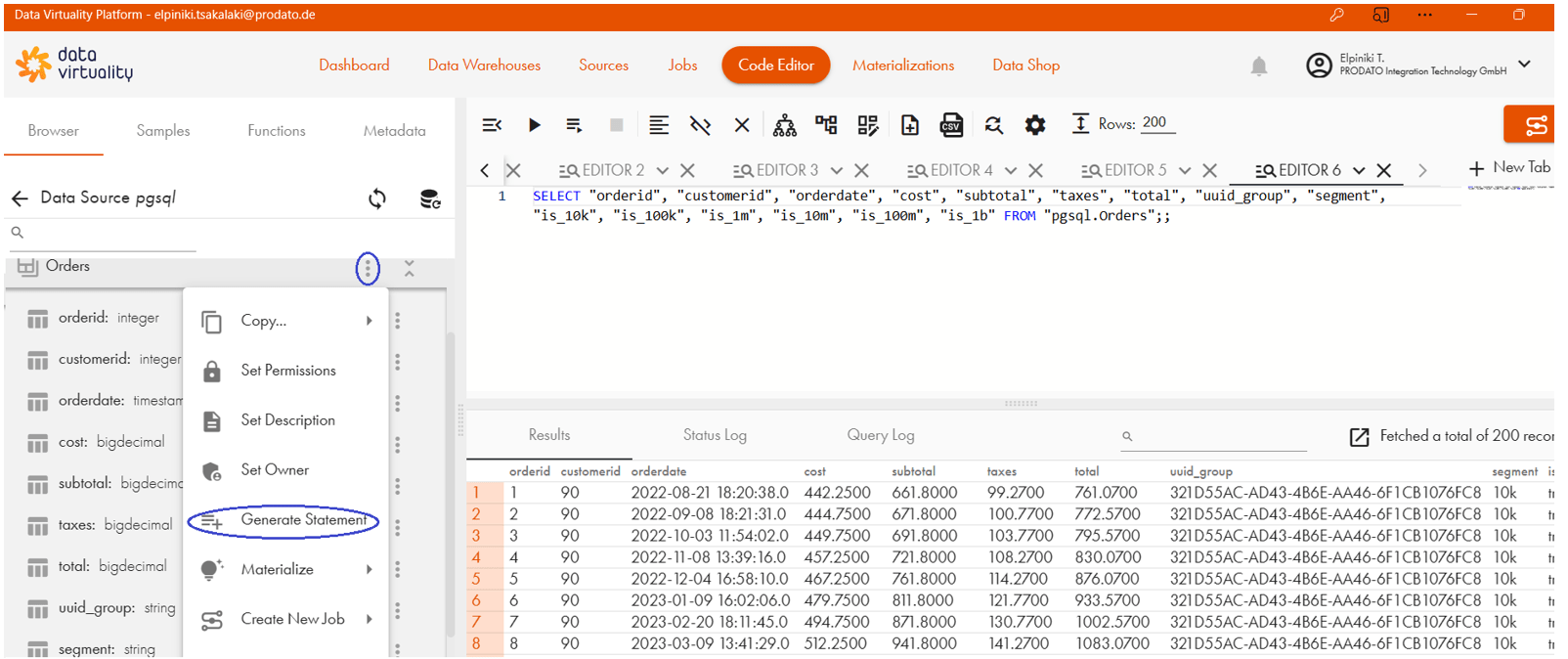
Bei der Anbindung der Datenquellen extrahiert die Data Virtuality Engine Metadaten und Schemas. Die Tabellen Customers aus mysql und Orders aus pgsql enthalten Vertriebsdaten über Kunden, Bestellungen, Umsatz (Revenue) und Kosten. Die Tabelle bankingcustomerinfo aus google_spreadsheets enthält detailliertere Kunden-Informationen. Die Datenobjekte können auf Code Editor → Data Sources → Datenquelle-Name → Objekt-Name → Generate Statement per SQL abgerufen werden:
Die Tabellen Customers und Orders können auf Code Editor → View Builder grafisch in der virtuellen View orders_customers kombiniert werden:
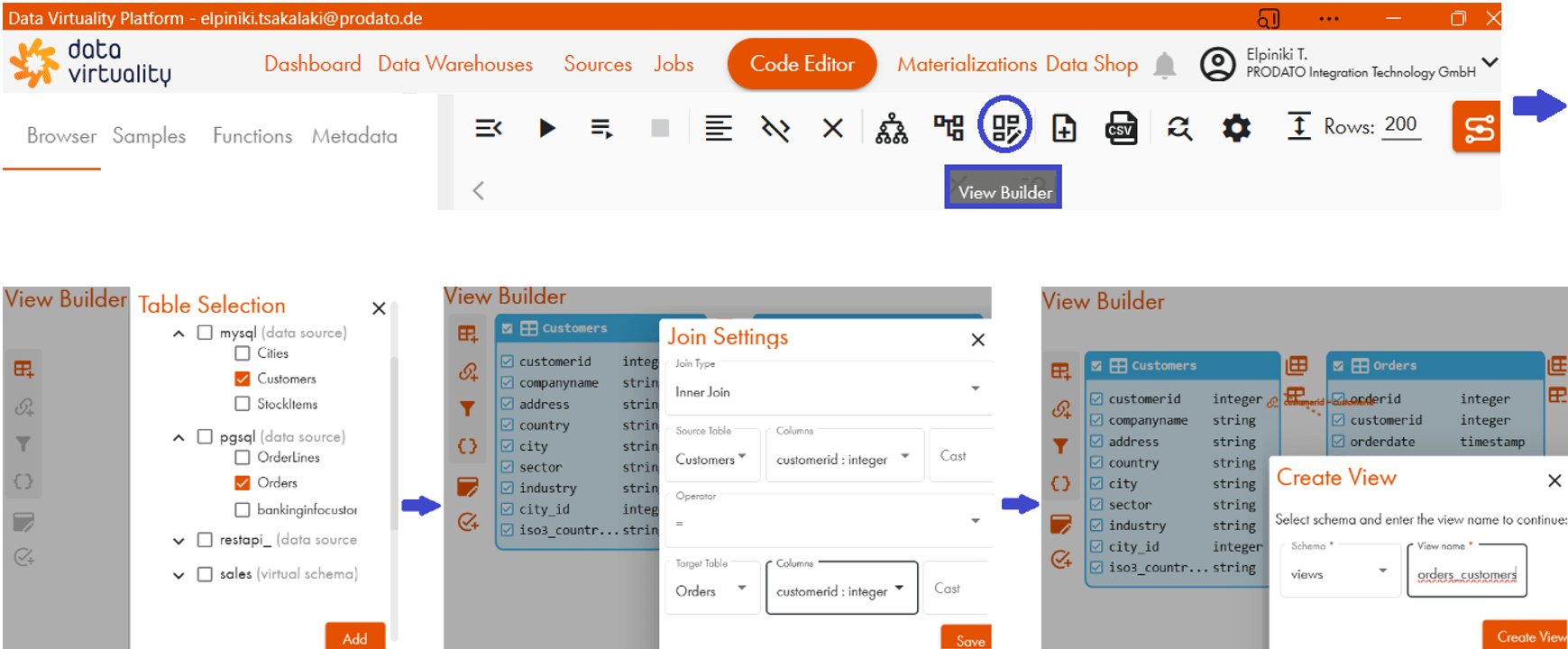
Alternativ kann die virtuelle View orders_customers in Code Editor per SQL erstellt werden:
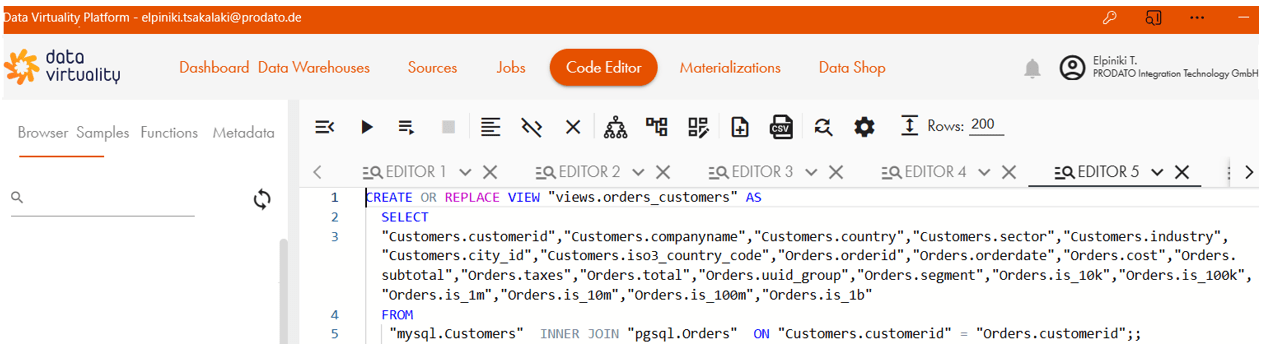
Datenauslieferung zu Client-Applikationen / Nutzern
Der Data Virtuality-Web Business Data Shop ist ein logischer Zugriffspunkt, wo Datenmengen veröffentlicht werden, um an unterschiedlichen Client-Systemen zur Verfügung gestellt werden zu können. Die Veröffentlichung der orders_customers in Data Shop kann über die Stored Procedure webBusinessDataShopPublish des Built-In Schemas SYSADMIN oder über eine Schnittstelle erfolgen:
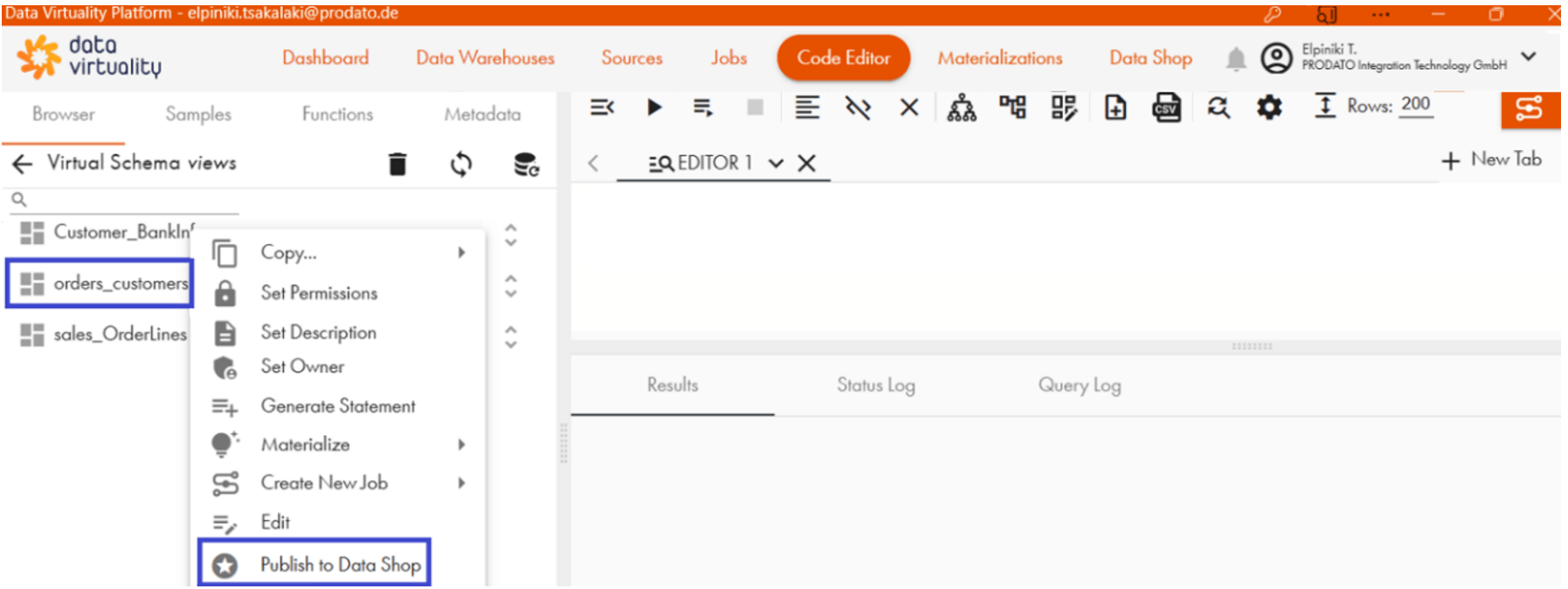
Die veröffentlichte View ist nur für Nutzer sichtbar, die über die Berechtigung zum Anzeigen dieser verfügen. Unterschiedliche Systeme und BI Tools können mit den im Data Shop verfügbaren Daten interagieren. Beim Klicken auf dem Python-Symbol:
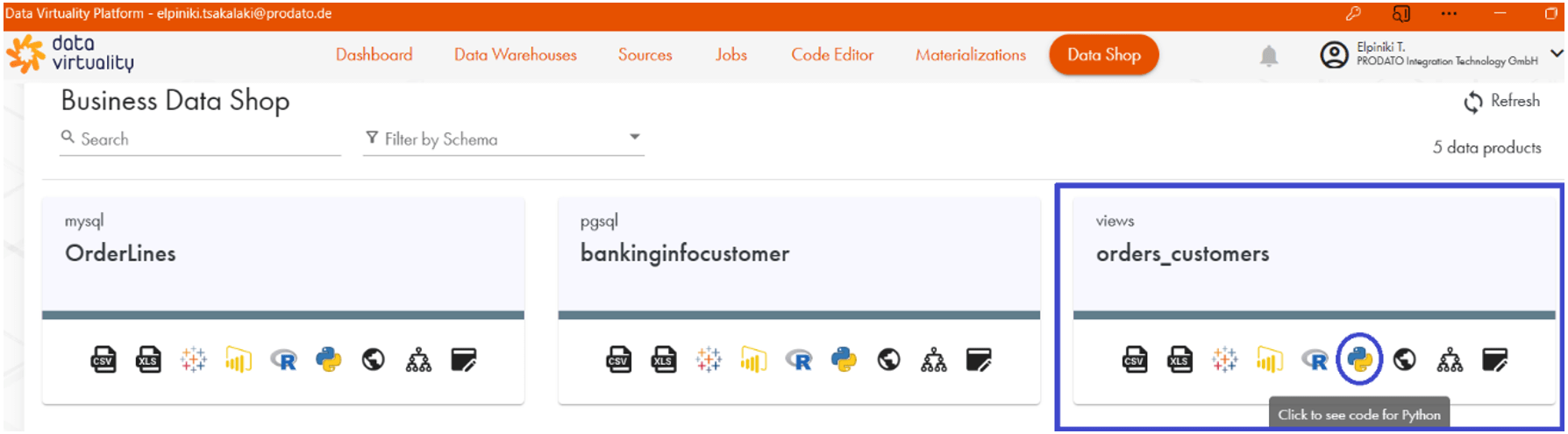
kann der folgende Code-Snippet erhalten werden:

Somit kann durch Python-Code mit dem psycopg2 Python-PostgreSQL Database Adapter auf den Data Virtuality Server zugegriffen werden.
Erstellung des KPI-Dashboards mit Python
In der Python-Datei app.py für die Einrichtung der Dashboard-App wird außer psycopg2 noch die Bibliothek Dash importiert, die zusammen mit Plotly die Visualisierung und Organisation der KPIs in einem Dashboard ermöglichen:

Dann werden erst die in Data Virtuality-Data Shop veröffentlichten Objekten als Lists (Built-In Python Datentyp) geladen und in pandas-Dataframes verwandelt:

Das Dataframe df über orders_customers wird bearbeitet, sodass „Bestelldatum“ der Index wird:

Erstellung von historischen Diagrammen
Nun können historische Graphen erstellt werden, z.B. über die tägliche Anzahl an Bestellungen:

Noch wird die Grafik fig bestehend aus zwei Diagrammen vorbereitet. Ein Diagramm ist über die Revenue (Subtotal) per Date-Time und das andere über den gleitenden 7-Tage-Durchschnitt des gesamten Tagesumsatzes:
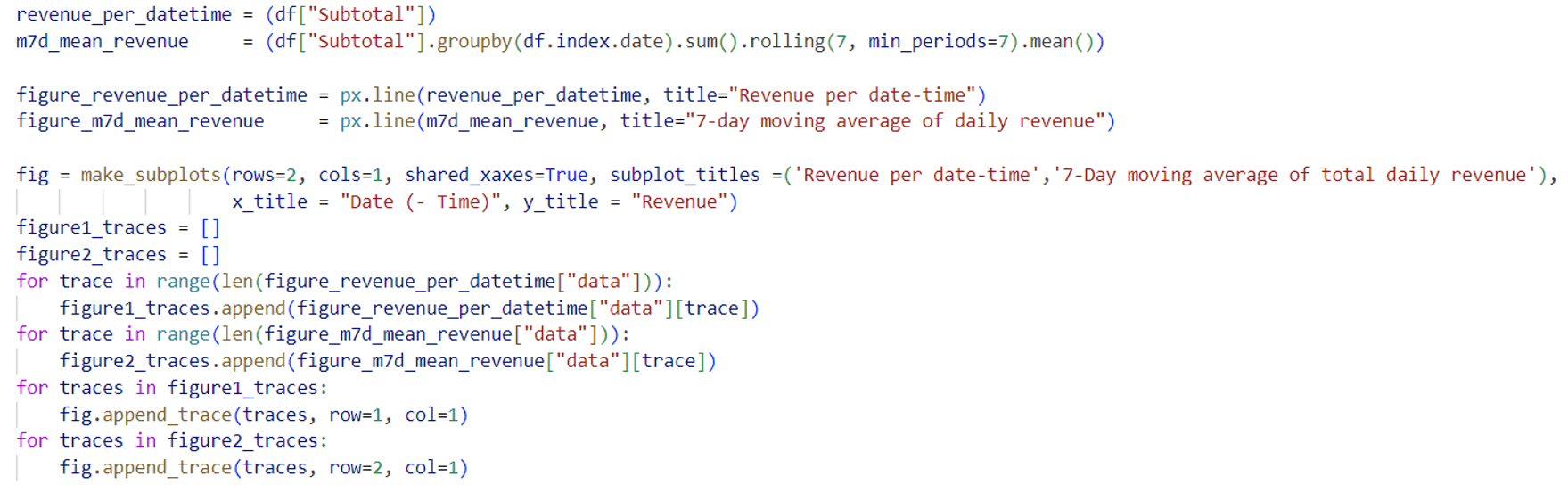
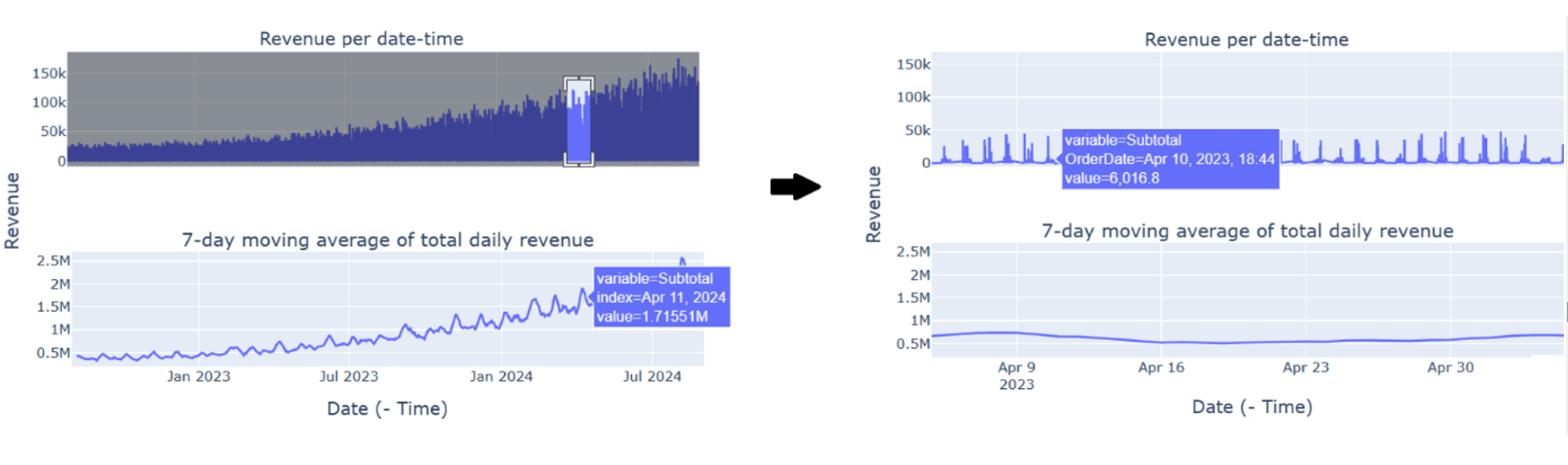
Hinzufügen von Diagrammen in Dashboard
Das Layout der Dashboard-App wird als eine Reihe von Spaltenzeilen erstellt. Mit dem Dash-Bootstrap-Component dbc.Row (Wrapper für Spalten) und dbc.Col werden die historische Grafiken in einer Dashboard-Zeile row_date_metrics organisiert, nachdem sie dem Dash-Core-Component dcc.Graph übergeben werden:

Darüber hinaus ermöglicht der div Wrapper für HTML5 das Strukturieren der Dash-Layouts mittels HTML-Tags. Dadurch können die Zeile mit den historischen Diagrammen und eine Zusammenfassung ins Dashboard hinzugefügt werden:

Interaktive Diagramme in Dashboard
Es wurde noch eine andere Dashboard-Zeile row_summary_metrics im oberen app.Layout hinzugefügt. Diese enthält folgenden Visualisierungen:
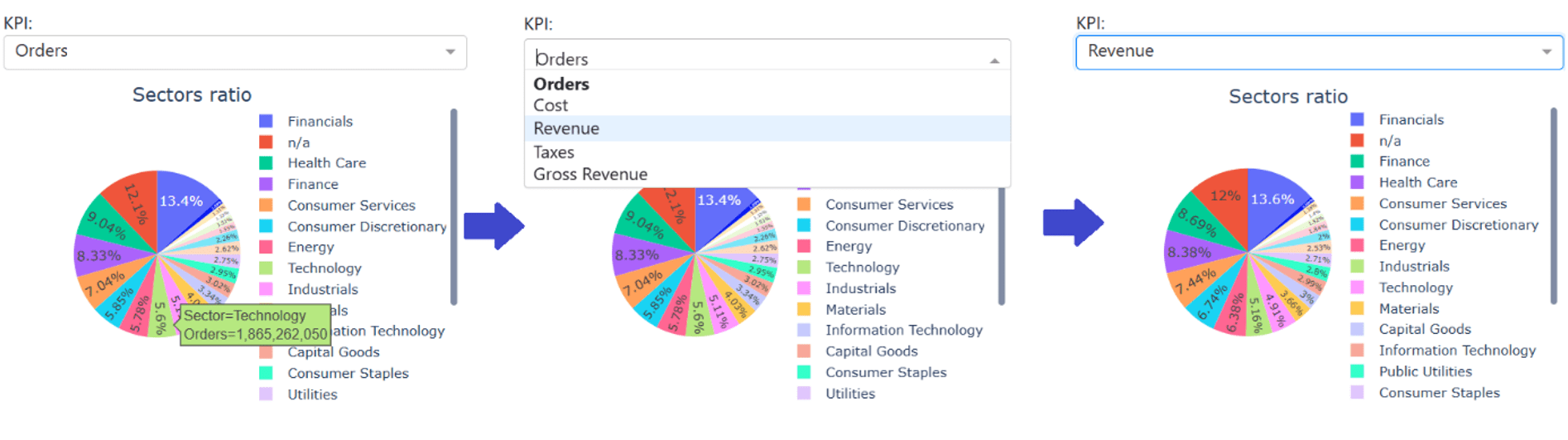
- ein Kreisdiagramm (id=graph) über die KPI-Zuteilung pro Sektor mit interaktivem DropDown (id=KPI) für die Selektion der gewünschten KPI-Metrik
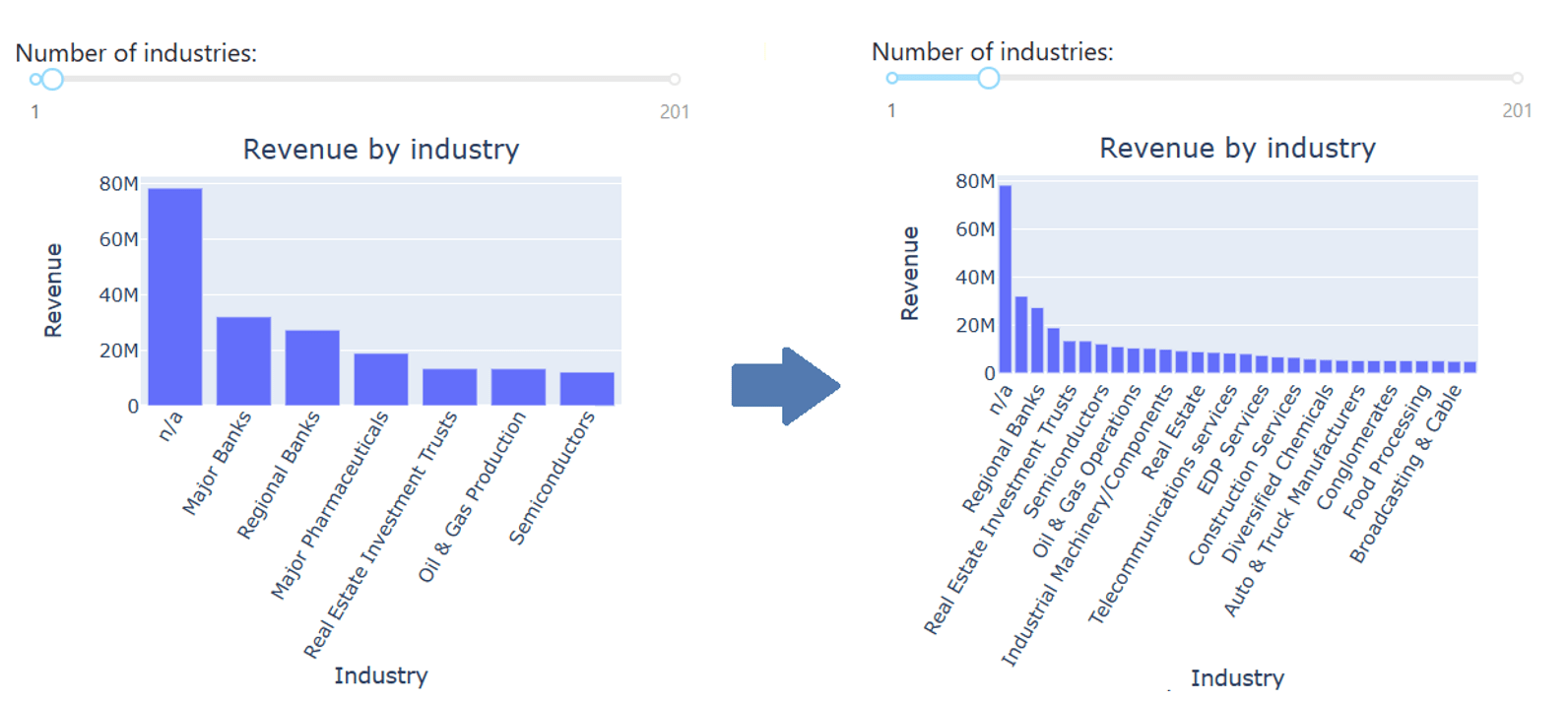
- ein Balkendiagramm (id=graph2) über die Revenue pro Industrie mit interaktivem Slider (id=IndN) für die Selektion der Anzahl an betrachteten Industrien IndN
- Eine Tabelle über Informationen zu Kunden mit Bank-Konto aus der virtuellen View bankingcustomerinfo erstellt durch DataTable

Das Kreisdiagramm wird in der Funktion generate_chart mit Eingabeparameter KPI definiert. Das interaktive DropDown mit id=KPI ist an einen Dash-App-Callback gekoppelt. Der Callback nimmt den aktuell selektierten DropDown-Wert für KPI und gibt ihn dem Kreisdiagramm mit id=graph aus:

Entsprechend wird das Balkendiagramm und dessen Callback für die Industrienanzahl IndN entwickelt:
Dashboard aufrufen
Die Dashboard-App kann von der Eingabeförderung aus mit python app.py gestartet werden:

Mit diesem Befehl wird das Dashboard auf dem Localhost-Server gestartet, der im Browser auf http://127.0.0.1:8050/ geöffnet werden kann. Wenn Dashboard-Komponenten angepasst werden, können die Änderungen auf dieser Seite in Echtzeit oder nach einem Neustart verfolgt werden.
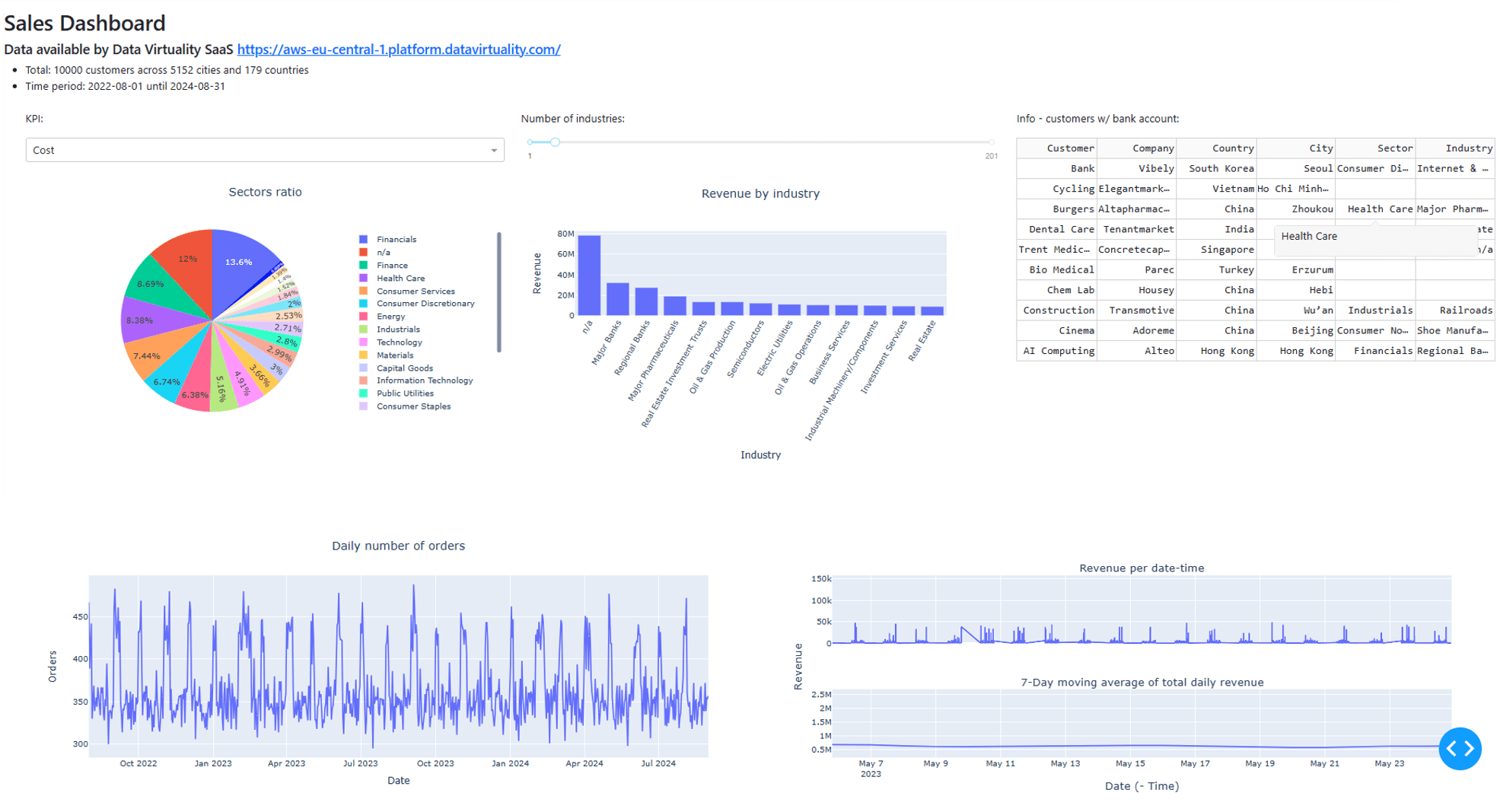
Die folgende Abbildung zeigt das endgültige Dashboard:
Fazit
Data Virtuality ermöglicht es, eine Anzahl an unterschiedlichen, disparaten Datenquellen einfach und schnell zu verbinden, die Business-Logik unkompliziert in einer Ebene von virtuellen Views zu organisieren, während der Data Virtuality Web Business Data Shop einen Datenkatalog bietet, der den Zugriff auf diesen Datenelementen erleichtert. Die Python API ermöglicht es Data Scientists außerdem Kennzahlen in ihrer gewohnten Umgebung zu analysieren und evaluieren und attraktive Visualisierungen und Dashboards zu entwickeln. Auch Data Lineage, Benutzungsinformation und die Implementierung der Data Mesh-Architektur bietet der Web Business Data Shop, was Data Virtuality zu einer gelungenen Plattform für agile Datenverwaltung und hohe Datenqualität für Datenanalysen macht.

