Überblick
Im ersten Teil dieser Blog-Serie wurden Large Language Models (LLMs) vorgestellt und darüber hinaus beleuchtet, warum diese gerade so im Trend sind und was LLMs so besonders macht. In diesem und letzten Teil der Blog-Serie wird die Intelligenz von LLMs und deren Einschränkungen betrachtet. Ist diese Künstliche Intelligenz tatsächlich „intelligent“? Inwiefern unterscheidet sich die Intelligenz des Menschen von der Intelligenz dieser KI? Darüber hinaus werden aktuelle Probleme und Einschränkungen von LLMs aufgezeigt und beschrieben, in welchen Fällen der Einsatz von LLMs sinnvoll und nützlich ist.
Wie intelligent sind LLMs?
Die Bezeichnung von LLMs wie GPT-4 als allgemeine künstliche Intelligenz ist zum aktuellen Zeitpunkt überzogen. Selbst ob GPT-4 überhaupt ein erster Schritt Richtung allgemeiner künstlicher Intelligenz sei, wird diskutiert.
ChatGPT und LaMDA haben den Turing-Test bestanden, was ohne Frage eine erstaunliche Leitung ist. Der über 70 Jahre alte Test ist nach dem heutigen Stand der Wissenschaft jedoch kein Beweis für (künstliche) Intelligenz mehr; Gedankenexperimente wie der Chinese-Room zeigen schon lange die Schwächen des Tests auf.
LLMs haben bereits viele für Menschen gemachte Tests bestanden: zuletzt schrieb GPT-4 Bestnoten in Tests über Kunstgeschichte, Biologie, Ökonomie, Mathematik und Psychologie. Diese Tests sollen jedoch Wissen testen, keine Intelligenz. Tests für Menschen können oft durch Auswendiglernen gelöst und bestanden werden. Etwas, in dem Computer traditionell sehr gut sind. Im Internet findet man ebenso viele Beispiele, bei denen ChatGPT simple Aufgaben nicht korrekt lösen kann, die einem Menschen sehr leichtfallen.
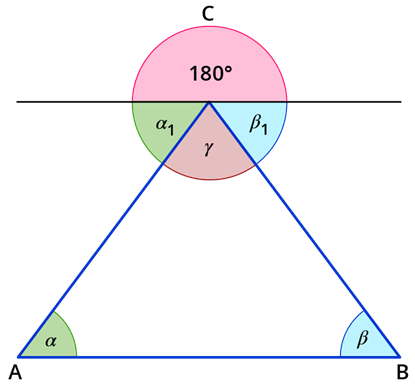
Ein Unterschied zwischen menschlicher und künstlicher Intelligenz kann anhand eines simplen Beispiels gezeigt werden: Winkelsumme im Dreieck. Wir gehen davon aus, dass eine KI und ein Mensch die Winkelsumme im Dreieck nicht kennen und sie selbst herausfinden wollen.
Die Intelligenz von Machine Learning (ML) Systemen stützt sich auf Daten. Füttert man eine KI mit den Innenwinkeln von tausenden Dreiecken, wird die KI lernen, dass die Winkelsumme im Dreieck ca. 180 Grad beträgt. Es lernt diesen Zusammenhang auswendig, hat aber das zugrunde liegende Prinzip nicht verstanden. Die KI weiß, dass die Winkelsumme im Dreieck 180 Grad beträgt, aber nicht warum.
Ein Mensch kann die Winkelsumme im Dreieck durch Logik herausfinden. Statt Daten zu analysieren können Menschen Axiome und bekannte Gesetze verwenden, um neue Zusammenhänge zu erkennen. In Abbildung 1 ist die Herleitung der Winkelsumme dargestellt. Mit Hilfe einer zur Grundseite parallelen Gerade an der Spitze des Dreiecks und des Wechselwinkelsatzes kann bewiesen werden, dass die Winkelsumme 180 Grad betragen muss. Der Mensch versteht, dass die Winkelsumme im Dreieck 180 Grad betragen muss, indem er dieses zu Grunde liegende Prinzip begreift. Eine solche Herleitung kann eine KI nicht selbst entwickeln.
Natürlich lernen auch viele Menschen Fakten auswendig, ohne den Beweis zu verstehen. Doch die Fähigkeit Logik anzuwenden, Annahmen zu treffen und dadurch zu lernen, zeichnet menschliche Intelligenz aus. Dies unterscheidet den Menschen aktuell von der künstlichen Intelligenz.
LLMs liefern oft Beweise als Antwort auf Fragen. Können sie deshalb Logik verwenden, um neue Zusammenhänge zu entdecken? Nein, denn auch LLMs lernen durch Daten, nicht durch Begreifen und Logik. So wie das Erlernen der Winkelsumme anhand von Daten erlernen LLMs den gesamten Beweis als Antwort auf eine Frage, ohne ihn zu verstehen. Wenn sie diesen Beweis dann als Antwort geben, wirkt es, als hätte das LLM diesen Zusammenhang begriffen.
Da LLMs auf riesigen Datenmengen trainiert werden, besitzen sie eine große Wissensbasis. Sie verinnerlichen nicht nur einzelne Fakten, sondern ganze Vorgehensweisen, Ideen und Konzepte. Zudem besitzen sie die Fähigkeiten, diese Ideen und Muster auf neue Weisen zu kombinieren. Auch dies lässt sie oft intelligenter wirken als sie tatsächlich sind.
In welchen Bereichen haben LLMs Probleme?
Das starke Verlassen auf Muster und der Fokus von LLMs auf das korrekte Generieren von Sprache führt zu Besonderheiten, die man bei der Verwendung von LLMs bedenken muss.
Kommen wir noch einmal auf das Beispiel mit den Dreiecken zurück. Auf die Eingabe „Beweise mir, dass die Winkelsumme im Dreieck 180 Grad beträgt“ gibt ChatGPT Beweise als Antwort, die die Annahme von 180 Grad Innenwinkelsumme während der Herleitung verwenden. Oft widerspricht sich die KI auch selbst (z. B. „Zwei parallele Geraden schneiden sich in Punkt D“).
Ein ähnliches Verhalten stellt die KI zur Schau, wenn man sie nach der Lösung eines abgeänderten Schaf-Wolf-Salat Rätsels fragt. In der Originalversion müssen Schaf, Wolf und Salat nacheinander über einen Fluss gebracht werden, wobei das Schaf nicht allein mit dem Wolf oder dem Salat gelassen werden darf. In der abgeänderten Version darf der Salat nicht allein mit Wolf oder Schaf bleiben. ChatGPT gibt auch bei dem neuen Rätsel die alte Antwort und lässt sich davon auch nicht durch neue Eingaben abbringen. Warum gibt ChatGPT diese falschen Antworten?
Die Antworten in diesen Beispielen sind feste Muster, die ChatGPT gelernt hat. Dass die Winkelsumme 180 Grad beträgt, ist eine solch grundlegende Regel, dass die KI sie selbst im Beweis verwendet. Das Rätsel wird normalerweise stets auf dieselbe Art gestellt, sodass die Variation nicht beachtet wird. Es wird die wahrscheinlichste Lösung ohne Logikkontrolle generiert.
Zudem sind LLMs in erste Linie für das Generieren von Sprache entwickelt worden. Das korrekte Beantworten von Fragen oder das Lösen von Aufgaben sind nur Nebenprodukte. Den Modellen ist es wichtiger eine grammatikalisch korrekte Antwort zu geben, als die richtige Antwort zu geben. Zusätzlich sind solche Unwahrheiten in den Antworten nur schwer zu erkennen. LLMs geben nicht zu, dass sie etwas nicht wissen. Sie geben falsche Antworten mit ebenso viel Selbstbewusstsein, wie richtige.
LLMs sind statistische Modelle, die stets nur die wahrscheinlichste Antwort liefern. Kleine Änderungen an der Ausgangslage können deshalb zu unterschiedlichen Antworten auf dieselbe Frage führen. Die LLMs verhalten sich wie ein Lehrer, der je nach Raumtemperatur, Wetter oder Zimmer, in dem er sitzt, denselben Aufsatz unterschiedlich bewertet. Demnach können LLMs sehr inkonsistente Antworten liefern.
Wann sind LLMs nicht sinnvoll?
Auch wegen dieser Probleme ist der Einsatz von LLMs nicht in allen Anwendungsfällen sinnvoll. Wenn konsistente Ausgaben oder spezifische Formate benötigt werden, sind LLMs möglicherweise wegen ihrer stochastischen Natur keine gute Lösung. Die Ausgabe von LLMs kann stark variieren. Diese Varianz kann beispielsweise durch Veränderung der Eingangsdaten oder einer Aktualisierung des Modells seitens des Herstellers verursacht werden.
Darüber hinaus sind LLMs in Bezug auf die Eingabegröße begrenzt, was bedeutet, dass große Datenmengen nicht effizient verarbeitet werden können. Das einfachste Beispiel ist das Zusammenfassen von Texten. Dokumente mit mehr als fünf Seiten müssen geteilt werden, was zu Qualitätsminderung der Zusammenfassung führen kann. Auch für die Mustererkennung auf großen Datenmengen sind andere Machine-Learning-Methoden besser geeignet.
LLMs zeichnen sich durch ihr Verständnis natürlicher Sprache aus, aber viele Prozesse erfordern kein Sprachverständnis. Spezialisierte ML-Lösungen können in vielen Fällen die generalistischen LLMs übertreffen, insbesondere wenn keine menschliche Interaktion erforderlich ist oder die Eingangsdaten numerisch sind.
Die Integration von LLMs in bestehende Prozesse erfordert sorgfältige Abwägungen in Bezug auf Nutzen und Wirtschaftlichkeit. LLMs erfordern oft einen anderen Ansatz und eine umfassende Anpassung des bestehenden Prozesses. Es ist wichtig zu prüfen, ob der Mehrwert, den ein LLM bieten kann, die Kosten der Prozessanpassung rechtfertigt.
Bei der Verwendung von LLMs besteht eine gewisse Abhängigkeit von den Anbietern. Personenbezogene Daten werden unter Umständen bei den Anbietern außerhalb der EU gespeichert und verarbeitet, wo oft weniger strenge Datenschutzgesetze gelten. Dadurch können sensible Informationen in die Wissensbasis der KI eingehen und damit öffentlich zugänglich werden. Unternehmen, die sensible oder vertrauliche Daten verarbeiten, sollten die Datenschutzrichtlinien und Nutzungsbedingungen der Anbieter sorgfältig prüfen.
Die Erstellung und das Training eines eigenen LLMs von Grund auf ist für einzelne Personen oder Unternehmen derzeit nicht praktikabel, da dies sehr hohe Kosten verursacht. Allein das Training eines großen LLM kann mehrere Millionen Euro kosten. Stattdessen ist es für die meisten Unternehmen sinnvoller, vorhandene Modelle zu nutzen und für deren Verwendung zu bezahlen. Es gibt jedoch auch frei verfügbare, vortrainierte Modelle, die lokal oder auf eigener Infrastruktur eingesetzt werden können. Diese sind jedoch meistens deutlich kleiner und bieten daher weniger Funktionen. Eingebettet in den richtigen Prozess, können diese Open-Source Modelle trotzdem einen großen Mehrwert bringen.
Bei PRODATO beschäftigen wir uns sowohl mit der angepassten Anwendung dieser Anbieterlösungen als auch mit frei verfügbaren Modellen, die auf der eigenen Infrastruktur oder Cloud-Instanz bereitgestellt werden können.
Wann sind LLMs nützlich?
Auch wenn bisher eher die Grenzen und Limitationen von LLMs angesprochen wurden, sind sie kein übertriebener Trend. In vielen Abläufen können sie effektiv eingesetzt werden und beschleunigen die Arbeit um ein Vielfaches.
Wie bereits erwähnt, ist die Fähigkeit der LLMs natürliche Sprache zu verstehen, der Grundpfeiler für ihre Effektivität. Als Schnittstelle zwischen Menschen und Programmen erlauben sie es auch Anfängern, komplexe Aufgaben zu lösen. Mit einem LLM-Plugin für Foto-Bearbeitungsprogramme können Laien beispielsweise beschreiben, wie ein Bild verändert werden soll, ohne dass Kenntnis über das komplizierte Zusammenspiel und Anwendung der verschiedenen Tools benötigt wird. Das Plugin führt die Bearbeitung dann automatisch aus. Dabei gibt der Mensch das, „Was“ vor und das LLM liefert das „Wie“. Besonders dann, wenn Menschen mit der KI oder Computerprogrammen interagieren sollen, bietet sich der Einsatz von LLMs an.
LLMs werden bereits erfolgreich für die Recherche, das Zusammenfassen von Informationen und das Generieren von Codes eingesetzt. Zudem werden ihre Fähigkeiten stetig durch Plugins ausgebaut. So liefert beispielsweise eine Integration an Wolfram Alpha bessere mathematische Fähigkeiten, OpenTable erlaubt das Reservieren von Restaurants und Expedia das Suchen nach Flügen. Darüber hinaus werden täglich neue Anwendungen veröffentlicht, auf die die LLMs zugreifen können.
Generell kann man sagen, dass LLMs immer dann unterstützen können, wenn das Problem durch Text oder Sprache beschrieben und gelöst werden kann. Sie ermöglichen es komplizierte Abläufe durch simple Eingaben durchzuführen und sind damit eine wichtige Komponente für die Zukunft von künstlicher Intelligenz.
Ausblick
Die Zukunft von Large Language Models ist vielversprechend und es ist wahrscheinlich, dass sie eine immer wichtigere Rolle in verschiedenen Bereichen spielen werden. Neue Plugins und Anwendungen sind dabei nur ein Teil der Entwicklung, denn auch die Modelle selbst werden ständig weiterentwickelt. Die großen Firmen sind sich der Schwächen ihrer aktuellen KI-Systeme bewusst und arbeiten an Lösungen. Nächste Iterationen von LLMs werden ihren Fokus auf Richtigkeit und Logik richten. Mit der fortschreitenden Entwicklung von KI-Technologien und immer größeren, verwendbaren Datensätzen werden Large Language Models in der Lage sein, noch komplexere Aufgaben zu bewältigen und noch bessere Ergebnisse zu liefern. Gleichzeitig wird die Bedeutung von Ethik und Verantwortung in der KI-Forschung und -Anwendung wichtiger werden. Außerdem sind Sicherheitsbedenken, vor allem im Bereich Datenschutz, nicht von der Hand zu weisen. Open-Source Modelle werden hier einige Lücken schließen können, das volle Potential der kommerziellen LLMs erreichen sie aktuell jedoch nicht. Für Anwendungen mit sensitiven Dokumenten und Informationen bieten sie jedoch einen großen Mehrwert.
Wir bei PRODATO beschäftigen uns sowohl mit der Anwendung von kommerziellen Modellen wie GPT und BARD, als auch mit dem Einsatz von lokalen Open-Source Modellen wie Falcon, Bert, BLOOM oder OpenAssistent. Wenn Sie Ihren Prozess mittels eines LLM optimieren möchten, stehen wir Ihnen gerne für eine Beratung und Umsetzung zur Verfügung.

