Bei der Entwicklung von Data Integration Jobs mit Talend gibt es meist die Anforderung, Daten aus zwei unterschiedlichen Quellen miteinander zu verknüpfen. Eine beispielhafte Anwendung hierfür ist z.B. das Nachschlagen von Verkaufspreisen für eine (ca. 900 Einträge kurze) Liste von Büchern. Nehmen wir für diesen Beitrag an, dass uns diese Liste als CSV Datei vorliegt.

Bücher haben (meist) eine ISBN, mit der sie eindeutig zu identifizieren sind. Hierdurch haben wir für unsere Aufgabe bereits einen Schlüssel, den wir zur Verknüpfung nutzen können. Weiterhin soll für unser Beispiel in einer PostgreSQL Datenbank eine Tabelle books_masterdata existieren, in der wir u.a. den Verkaufspreis zu einer ISBN gegeben haben. Diese Tabelle enthält mit über 600.000 ISBNs deutlich mehr Datensätze als unsere zu ergänzende Liste.
Das übliche Vorgehen: Die tMap
Für unsere Anforderung bietet das Talend Studio bereits eine grundlegende Komponente an: Die tMap. Mit dieser können wir ankommende rows aus mehreren Quellen über Schlüsselspalten verknüpfen. Unsere erste Quelle, der Main input, ist die gegebene CSV Datei. Zu dieser wollen wir Daten aus einer zweiten Quelle, der books_masterdata Tabelle, hinzufügen. Daher ist die zweite Quelle unser Lookup. Die in einer tDBInput Komponente verwendete Abfrage sieht wie folgt aus:
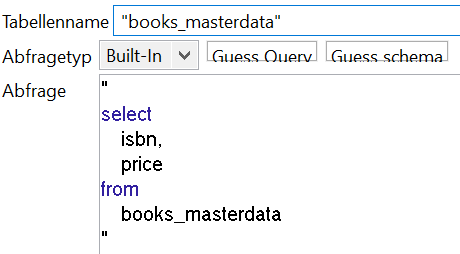
Unsere tMap Verknüfung konfigurieren wir als Left Outer Join (falls wir keinen Preis finden, wollen wir die Zeile in der CSV trotzdem behalten). Außerdem wählen wir die Erste Übereinstimmung als den hinzuzufügenden Preis (da wir wissen, dass es nur einen Preis geben wird, müssen wir nach einer Übereinstimmung keine weiteren suchen). Nach allen Konfigurationen sieht unser erstellter Job dann wie im folgenden Bild aus:
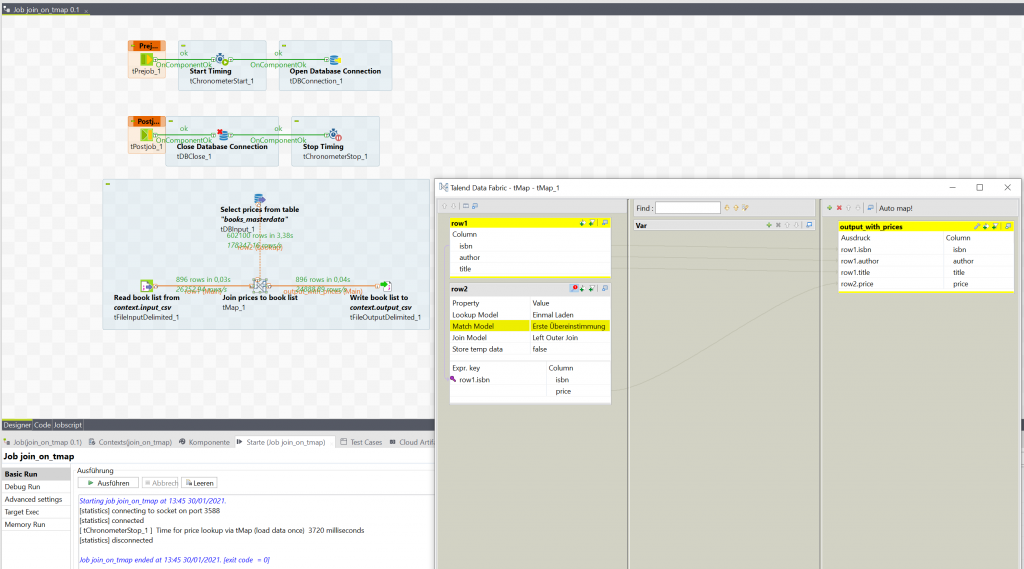
Im Screenshot können wir auch direkt eine beispielhafte Ausführung sehen. Unser Job braucht 3,7 Sekunden, um die Daten zu verknüpfen. Der Großteil der Zeit wird dabei für das Laden der Preisdaten aus der Datenbank benötigt. Von den über 600.000 geladenen Zeilen benötigen wir allerdings den Großteil gar nicht für unsere Aufgabe. Dies bedeutet, dass wir viel Zeit mit dem Warten auf die Datenübertragung verbringen, die wir uns eigentlich sparen könnten.
Optimierung in Talend: Laden bei jeder Zeile
Die tMap Komponente bietet uns eine erste Lösung an, wie wir dieses Problem umgehen können. Das Lookup Model lässt sich von Einmal Laden auf Laden bei jeder Zeile umstellen. Hierdurch wird unsere tDBInput Komponente mit den Lookup Daten für jede Zeile aus der CSV Datei einmal ausgeführt. Daher können wir jetzt jede Abfrage auf eine einzelne ISBN einschränken, sodass nur noch so viele Zeilen übertragen werden müssen, wie in der CSV Datei vorhanden sind. Unsere Datenbankabfrage sieht damit leicht verändert aus:
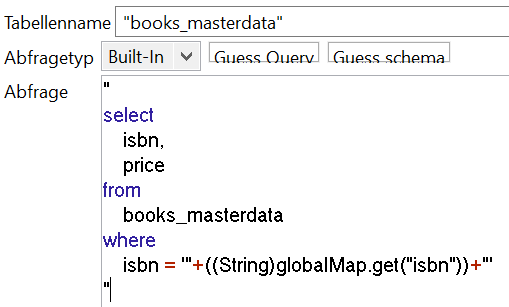
Die ISBN, auf die eingeschränkt werden soll, holen wir dabei aus einer globalMap Variable, welche direkt in der Konfiguration der tMap befüllt werden kann. Im Rahmen dieses Beispiels soll das direkte Einbetten der isbn Variable in die Query durch Stringverkettung genügen. Für den Einsatz in produktiven Umgebungen sollte hier aber ein Prepared Statement genutzt werden.
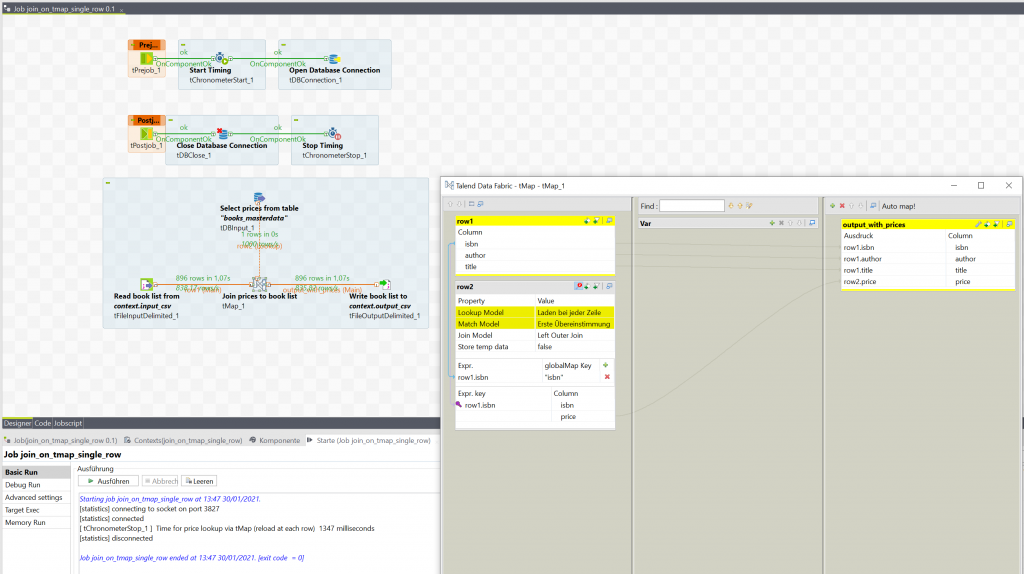
Wir stellen fest, dass durch diese Änderungen die für unseren Job benötigte Ausführungszeit auf 1,3 Sekunden gefallen ist – eine deutliche Verbesserung. Es sei angemerkt, dass diese Verbesserung u.a. dadurch möglich wird, dass es für die books_masterdata Tabelle einen Index mit der Spalte isbn gibt. Das ist zwar eine typische Konfiguration, ohne diese wäre das Laden bei jeder Zeile aber wahrscheinlich deutlich langsamer als der ursprüngliche Job.
Geht da noch mehr? – Joins in der Datenbank
In unserem Beispiel könnten wir mit dem bisherigen Ergebnis zufrieden sein. Sowohl 1,3 Sekunden, als auch 3,7 Sekunden sind akzeptable Zeiten für unsere Aufgabe. Sollten die Anforderungen allerdings steigen und mehr Zeilen in der CSV Datei oder der Datenbank vorhanden sein oder noch andere Werte aus weiteren Quellen verknüpft werden, müssen wir unser Vorgehen möglicherweise weiter optimieren. Im Gegensatz zum Problem unserer ersten Job Variante, dass wir zu viele unbenötigte Daten laden, haben wir nach unserer Optimierung nun sehr viele einzelne Abfragen, die unseren Job ausbremsen. Wir können uns diese einzelnen Abfragen aber sparen, wenn wir den durchzuführenden Join von unserem Talend Job, wo er in der tMap stattfindet, in die Datenbank verschieben. Hierzu müssten allerdings unsere Zeilen aus der CSV Datei in der Datenbank vorliegen. Das können wir über eine temporäre Tabelle realisieren. Diese lässt sich in der PostgreSQL Datenbank anlegen und existiert automatisch nur für die aktuelle Session – in unserem Fall also bis der Talend Job endet.
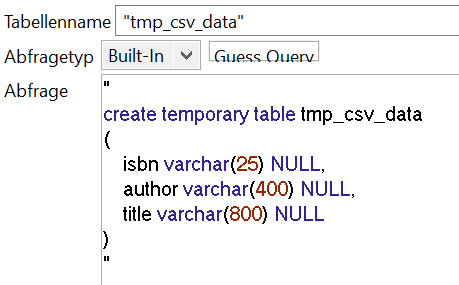
Während der Ausführung des Jobs können wir diese Tabelle aber genauso wie eine normale Tabelle nutzen, d.h. wir können unsere CSV Daten über die Verbindung einer tFileInputDelimited und einer tDBOutput Komponente in die Datenbank laden. Danach können wir unseren Join direkt ohne tMap in der Query einer tDBInput Komponente durchführen.
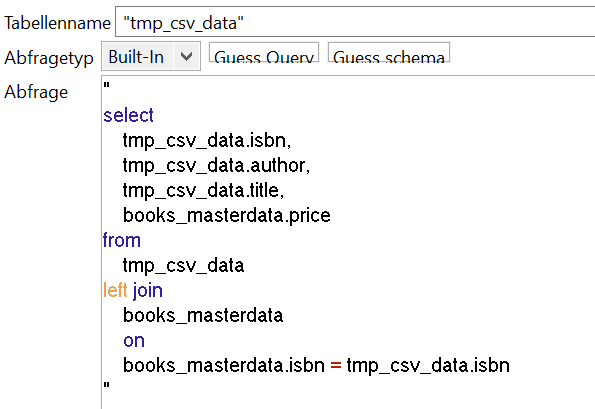
Die ausgehende row dieser Komponente können wir dann direkt ohne weitere Zwischenschritte mit einer tFileOutputDelimited Komponente verbinden, um unsere Ergebnisse in die Ausgabedatei zu schreiben.
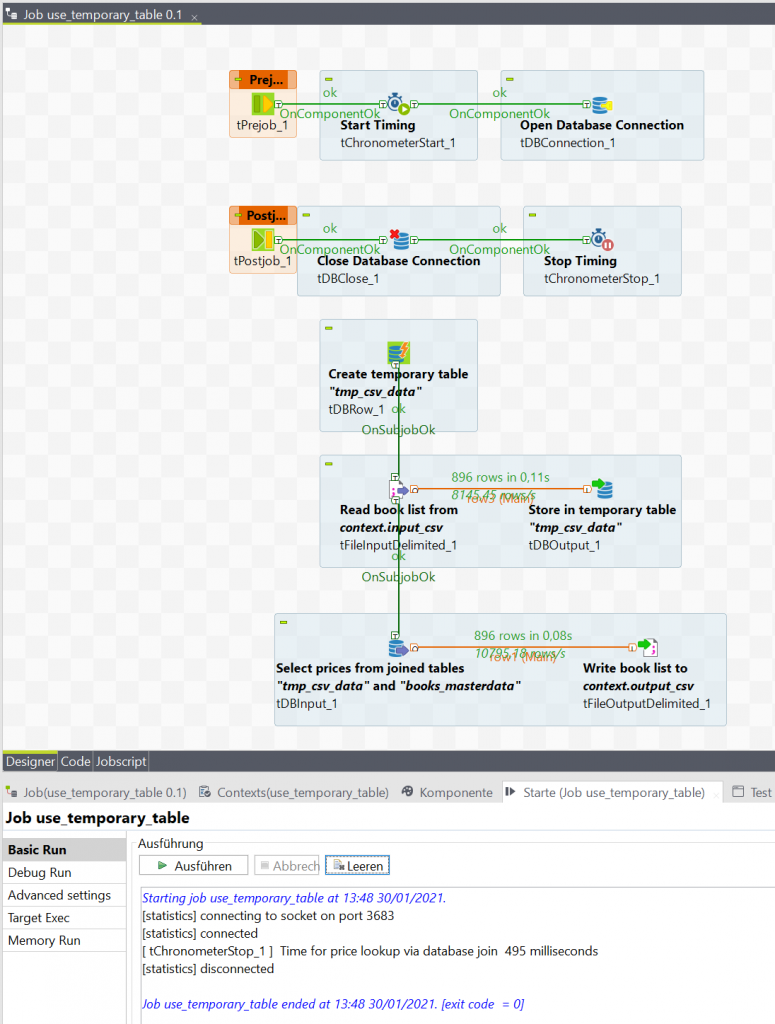
Durch dieses Vorgehen reduzieren wir die Ausführungszeit nochmals deutlich auf 0,5 Sekunden, erreichen also wieder eine klare Verbesserung. Alle drei gezeigten Job Varianten produzieren natürlich die gleiche Output Datei.

Wir konnten also sehen, dass die Verlagerung eines Joins aus der tMap des Talend Jobs in die Datenbank deutliche Vorteile im Bezug auf die Ausführungszeit bringt. Gerade bei komplexen Datenlagen kann diese Optimierung einen wichtigen Unterschied machen. Die Implementierung des Verfahrens bedarf allerdings einer Kosten-Nutzen-Abwägung. Der Zugewinn an Geschwindigkeit wird durch einen komplexeren Job erkauft. Entwickler, die den Job zukünftig bearbeiten sollen, müssen sich nicht nur mit Talend-Features sondern auch mit dem Konzept der temporären Tabelle auseinandersetzen – eine sinnvolle tNote kann hier den Zugang erleichtern. Das Vorgehen eignet sich übrigens nicht nur für PostgreSQL Datenbanken – so stellen z.B. auch Oracle Datenbanken temporäre Tabellen (mit leichten Unterschieden; bei Oracle sind z.B. nur die Zeilen in der Tabelle an die aktuelle Session/Transaktion gekoppelt, die Tabelle selbst existiert aber global über die Session hinaus) bereit, die für dieses Vorgehen geeignet sind. Bei Verwendung einer Oracle Datenbank erkennt man auch einen Vorteil der temporärem Tabelle gegenüber dem Erstellen einer in-Bedingung mit den ISBNs in der Lookup-Query: Während die in-Bedingung bei Oracle auf 1000 Elemente beschränkt ist, gibt es für die temporäre Tabelle kein Zeilenlimit.

