Process Mining ist in aller Munde und hat sich längst aus einem rein wissenschaftsgetriebenen Umfeld gelöst– das zeigt nicht zuletzt die Einstufung des Münchner Process Mining Unternehmens Celonis als „Decacorn“ mit einem Marktwert von über 11 Milliarden Dollar oder die Übernahme von Signavio durch SAP im Jahr 2021.
Der Hype ist keinesfalls übertrieben, denn je mehr Prozesse digitalisiert ablaufen, desto mehr (Log-) Daten entstehen. Dies bietet Unternehmen verschiedenster Branchen die Möglichkeit einen unverfälschten Blick auf ihre Prozesse zu werfen.
Process Mining will gelernt sein
Und doch: Process Mining will gelernt sein und kann unter falscher Verwendung zu fatalen Fehlannahmen führen. Denn während die Prozessverläufe in Prozessmodellen klar geregelt sind, sieht dies in der Praxis meist ganz anders aus. Prozessdurchläufe werden abgebrochen, Schritte in anderer Reihenfolge erledigt als beabsichtigt, Events unter unterschiedlichen Bezeichnungen in unterschiedlichen Systemen geführt. Spagetti-Prozesse aus denen (zunächst) keinerlei Informationen entnommen werden können, sind die Folge:
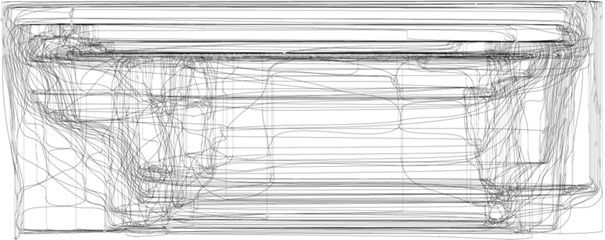
Keine Seltenheit: Viele unterschiedliche Prozessverläufe machen es schwierig Erkenntnisse aus den Log-Daten zu gewinnen
Ein strukturiertes Vorgehen, um Erkenntnisse aus den Prozessen zu gewinnen
Um diese Unübersichtlichkeiten zu vermeiden, sind verschiedene Stellschrauben zu beachten, die in der folgenden Reihenfolge abgearbeitet werden können:
1. Die Wahl der Datenbasis und des Datenmodells
Bevor mit dem Minen begonnen werden kann, ist analog zu Data Mining Verfahren die Datenbasis zu bestimmen und zu eruieren, wie diese aufzubereiten ist. Grundlegend ist dabei ein sogenannter Event Table der mindestens die Attribute „ID der Durchläufe“, „Aktivitäten“ und „Timestamp“ beinhaltet. Die Aufbereitung der Informationen zu den einzelnen Durchläufen erfolgt in der Regel analog zur Struktur in Data Warehouses als Star oder Snowflake Schema.
Die richtige Auswahl der Attribute ist nicht immer selbsterklärend. So können Aktivitäten auf verschiedenen Abstraktionsebenen liegen, Timestamps unterschiedlich festgelegt werden (z.B. zu Beginn einer Aktivität oder bei einer bestimmten Aktion) und Durchläufe unterschiedlich interpretiert werden. Für Standardprozesse wie „Purchase-to-pay“ oder „Order-to-cash“ bietet Process Mining Software mittlerweile in der Regel sogenannte Prozess-Konnektoren an, die auf Grundlage der Datenbasis ein geeignetes Datenmodell vorschlagen.
2. Die Wahl der richtigen Abstraktionsebene
Auch wenn wir die Datenbasis und das Datenmodell richtig ausgewählt haben, wird uns die Vielzahl der Prozessdurchläufe voraussichtlich vor Problemen stellen. Aus diesem Grund wurden verschiedene Aggregationsalgorithmen entwickelt, die auf Basis der Häufigkeit der Durchläufe die „wichtigsten“ Prozessvarianten anzeigen. Ein Beispiel dafür ist der Variant Explorer von Celonis:
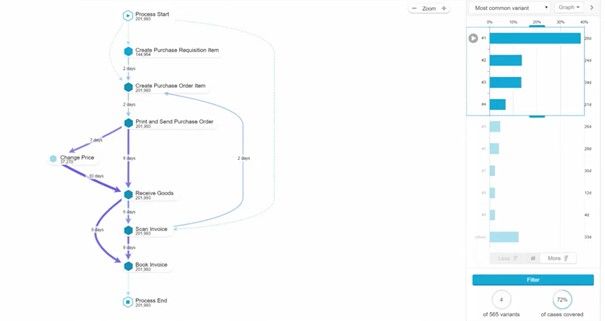
Der Celonis Variant Explorer bietet die Möglichkeit sich die häufigsten Prozessdurchläufe genauer zu betrachten
Die Ansichten sind flexibel anpassbar. So können Filter auf bestimmte Aktivitäten gelegt werden oder vordergründig die Varianten mit den längsten Durchlaufzeiten angezeigt werden.
3. Die Wahl der passenden Prozessmodellierung
Neben der Art der Variantenreduktion ist die Frage nach der Art der Prozessmodellierung entscheidend für eine transparente Prozessbetrachtung. Die Verläufe lassen sich mit unterschiedlichen Modellierungssprachen visualisieren, welche jeweils Vor- und Nachteile mit sich bringen. Zur Exploration der Varianten werden aufgrund des einfachen Verständnisses und der Filteroptionen oft Directly Follows Graphs eingesetzt. Diese haben jedoch gegenüber Petri Nets oder BPMN-Diagrammen den Nachteil, dass sie keine parallelen Aktivitäten abbilden können.
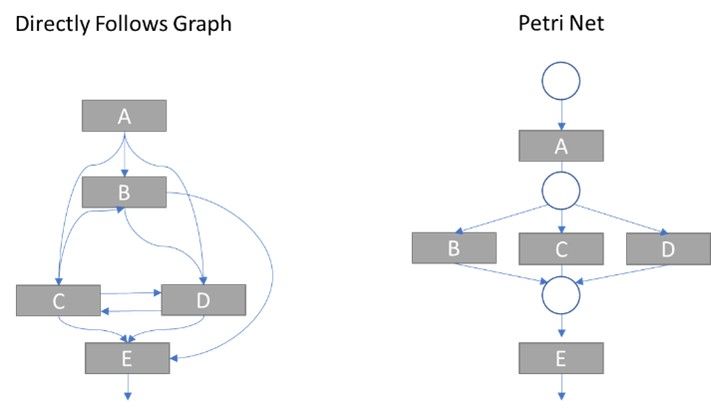
Parallele Aktivitäten können bei Directly Follows Graphs zu Problemen führen
Das kann wiederum dazu führen, dass die eigentlichen „Happy Paths“ also die Standarddurchläufe in der Aggregation verschwinden. In der Praxis werden deshalb in aller Regel über sogenannte Induktive Miner Verfahren zusätzlich zu den Variant Explorer-Ansätzen induktiv Prozessmodelle erstellt, die mit den aggregierten Verläufen abgeglichen werden können.
4. Die richtigen Schlüsse ziehen
Wunderbar, das Prozess-Wirrwarr ist entschlüsselt! Doch was stellen wir nun damit an? Neben den drei klassischen Anwendungsfeldern Process Discovery, Conformance Checking, ermöglicht es Process Mining Automatisierungspotenzial in Prozesen zu identifizieren. Daneben bietet sich die Aufbereitung der Daten in den Event Tables für den Einsatz von Machine Learning Algorithmen an. So können Cluster- oder Assoziationsalgorithmen implementiert oder auf eine abhängige Variable optimiert werden, um Entscheidungsunterstützung zu forcieren. Es scheint nicht verwunderlich, dass mittlerweile Python Code über Jupiter Notebooks direkt in Celonis eingebunden werden kann, während umgekehrt mit PM4PY eine Python Bibliothek für Process Mining entwickelt wird – das Potenzial von Process Mining ist noch lange nicht ausgeschöpft.
Die beschriebene Problematik kommt Ihnen bekannt vor?
Kommt Ihnen das beschriebene Problem bekannt vor bzw. haben Sie Schwierigkeiten damit, die richtigen Erkenntnisse aus Ihren Prozessdaten zu ziehen? Dann sprechen Sie mit uns! Wir unterstützen Sie von der Zielsetzung über die Wahl der Technologie bis zur Entscheidungsfindung und begleiten Sie im operativen Einsatz.
Sie wollen mehr zum Thema Process Mining oder Business Process Intelligence im Allgemeinen erfahren? Dann schauen Sie sich hier die entsprechenden Inhaltsseiten an oder sprechen Sie uns direkt an.

Prodato verbindet.
Autor
Jonas Weigert
