Überblick
Prognosen für zukünftige Verkäufe können Unternehmen dabei helfen, fundierte Entscheidungen auf der Grundlage von Daten zu treffen. Diese Prognosen können genutzt werden, um die Ressourcen und das Budget des Unternehmens besser zu planen und zu verwalten.
Durch die Nutzung von statischen Modellen und Machine Learning-Algorithmen können genauere und zuverlässigere Prognosen erstellt werden. Die Algorithmen analysieren historische Daten und können Trends und Muster erkennen, die menschliche Analysten möglicherweise übersehen würden.
SAP HANA ist eine leistungsstarke In-Memory-Datenbank und bietet eine umfassende Lösung für verschiedene statistische Modelle und Machine Learning Anwendungen. Einen allgemeineren Überblick über die Funktionalitäten von SAP HANA erhalten Sie in diesem Blogartikel: https://prodato.de/machine-learning-auf-sap-hana/ . Im Folgenden gehen wir auf die Umsetzung eines Sales Forecast mit SAP HANA ein.
Datenbasis
Es liegen wöchentliche Verkaufszahlen von 14 Stores mit je 48 Departments über 3 Jahre vor. Für jedes Department in jedem Store soll ein Forecast für das folgende Jahr berechnet werden, was sich auf insgesamt 672 Modelle beläuft.
Wöchentlich aggregierte Verkaufszahlen für die Merkmale Store und Departement.
Umsetzung
Interface
Der Machine Learning Use Case wurde auf SAP HANA mit der Programmiersprache Python umgesetzt. Die Python API ermöglicht den Zugang zur HANA über Jupyter Notebooks. Diese ermöglichen es Benutzern, interaktive Dokumente zu erstellen, die Code, visuelle Darstellungen und erläuternde Texte in einer einzigen Umgebung vereinen. Die nachfolgende Abbildung zeigt einen Ausschnitt eines Jupyter Notebooks, indem die Verbindung zur Datenbank mittels des Pakets hana_ml hergestellt wird.
Über diese Bibliothek werden auch die Befehle zur Ausführung von Algorithmen auf SAP HANA an die Datenbank übermittelt. Ebenso können die Daten von SAP HANA in ein pandas Dataframe Objekt geladen werden und ermöglichen so Analysen auf lokalen Rechner mit dem vollen Leistungsumfang von Python und lokal installierten Paketen.

Jupyter Notebook mit Verbindung zur HANA Datenbank. In Jupyter Notebooks kann ausführbarer Code direkt mit einer Dokumentation in Textform verbunden werden.
Algorithmus
Für den Forecast wurde der Algorithmus AutoARIMA aus der Predictive Analytics Library (PAL) mit einer wiederkehrenden Saisonalität von einem Jahr genutzt. Die PAL ist eine der zwei eingebetteten Machine Learning Bibliotheken von SAP HANA. Die Auto-ARIMA-Funktion optimiert die Parameter eines saisonalen ARIMA-Modells gemäß einem Informationskriterium wie AICc, AIC oder BIC und speichert das beste Modell.
Für alle 672 Modelle belief sich für diesen Use Case die Rechenzeit auf 37 Minuten. SAP HANA ermöglicht paralleles Training von Machine-Learning-Modellen, was zu einer schnelleren Verarbeitung großer Datenmengen und einer beschleunigten Modellentwicklung führt. Die Anzahl der Modelle, die gleichzeitig auf SAP HANA trainiert werden können, hängt der verfügbaren Rechenleistung ab.
Die folgende Abbildung zeigt exemplarisch einen Forecast (orange) zusammen mit den Trainings- und Testdaten (blau).
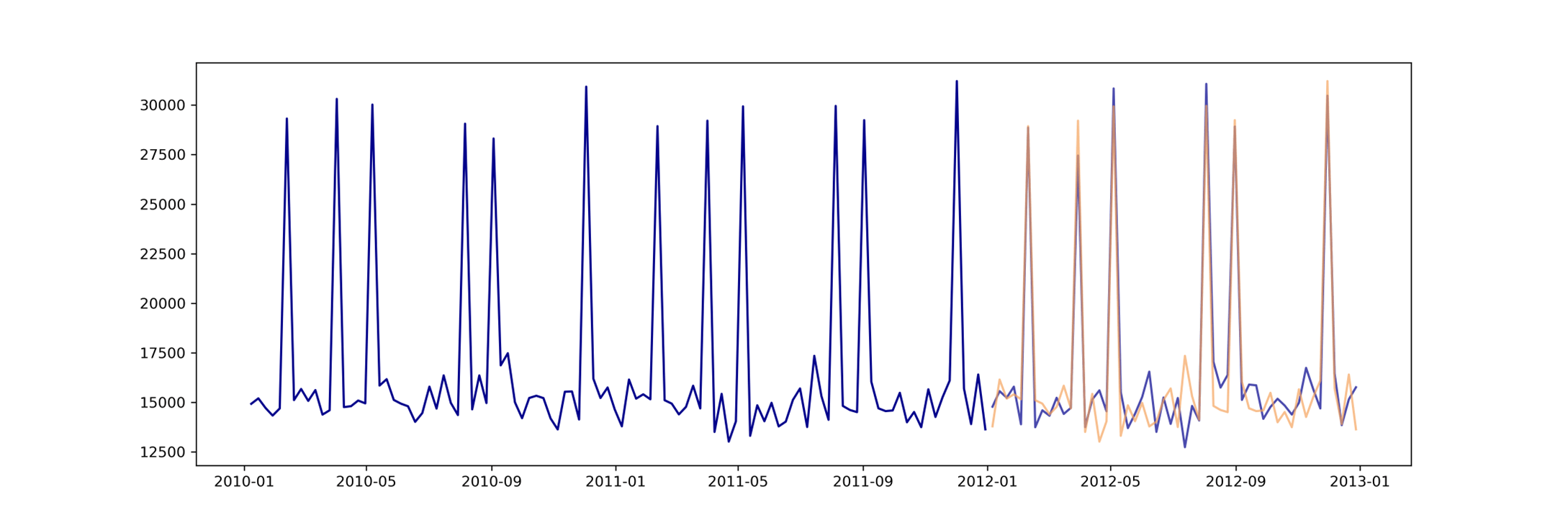
Forecast (orange) und Trainings- und Testdaten (blau) für Store 1 und Departement „Automotive“. MAPE 0.064094.
Modell Verwaltung
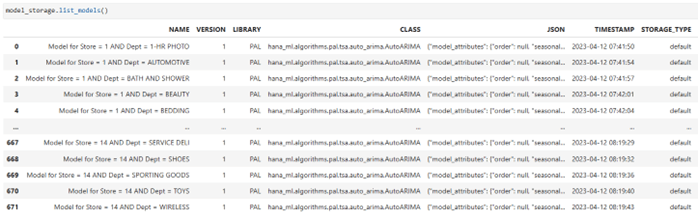
Machine Learning Modelle werden in SAP HANA mit dem Paket ModelStorage verwaltet und versioniert, siehe Bild. Die Modellparameter und Evaluationsmetriken werden pro Modell in Tabellenform gespeichert.
Evaluation
Für die Evaluation des Forecasts wurde der Mean Absolute Percentage Error zwischen dem Forecast und den Testdaten berechnet. Einen guten oder sehr guten Wert von unter 0.2 erreichten insgesamt 528 der 672 Modelle. Die Abbildung zeigt die Verteilung der MAPEs aller Modelle.
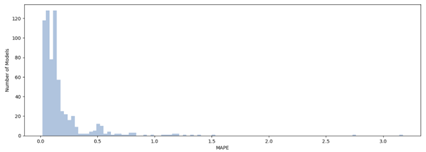
Anzahl der Modelle mit entsprechendem Mean Absolute Percentage Error (MAPE).
Fazit
Warum Machine Learning?
Ein automatisierter Sales Forecast kann Unternehmen viel Zeit und Ressourcen sparen. Manuelle Prognosemethoden erfordern in der Regel eine große Menge an Daten, die manuell gesammelt, überprüft und analysiert werden müssen. Mit SAP HANA können Unternehmen diesen Prozess automatisieren und Prognosen schneller und genauer erstellen. Darüber hinaus können durch die Optimierung der Geschäftsstrategie und die Steigerung der Effizienz möglicherweise auch Kosteneinsparungen erzielt werden.
Warum mit SAP HANA?
SAP bietet mit den zwei Bibliotheken eine umfangreiche Menge an statistischen Modellen und Machine Learning Algorithmen. Die Python API ermöglicht es Data Scientists außerdem Modelle in ihrer gewohnten Umgebung zu entwickeln und zu evaluieren. Das Trainieren von Machine-Learning-Modellen ist sehr performant, da SAP HANA speziell für die Verarbeitung großer Datenmengen und die parallele Verarbeitung von Daten ausgelegt ist. Auch Pakete für die Verwaltung und Versionierung von Modellen sind vorhanden, was SAP HANA zu einer wirklich gelungenen Plattform für Machine Learning Use Cases und statistische Analysen macht.

Prodato verbindet.
Autorin
Magdalena Reinelt
